Fuck ICE. Fuck Customs and Border Protection. Fuck Trump. They're criminals. The current US federal administration is massively violating civil rights, straight up lying about murder investigations and preventing evidence collection or hearings in a court of law. They must be opposed and eventually prosecuted in a court of law.
I wanted to play Age of Empires 2: Definitive Edition on my Debian 11 machine using amdgpu with an RX 580 8GB gpu and dual monitors. It works fine on steam but when I move my mouse to the right side of that monitor's screen to 'push' the map around in the RTS game the mouse instead slides off the game monitor and onto my second monitor. All of the online comments said to use gamescope like 'gamescope --force-grab-cursor -f -- %command% ' for this.
But unfortunately gamescope is literally an entire wayland environment that requires a dozen bleeding edge deps with tens of thousands of lines of code. For me it looked infeasible and I quickly gave up after my meson was too old. But mostly because of the hundreds of MB of source code for all the deps I knew would never compile.
superkuh@janus:~/app_installs/gamescope$ meson setup build/
The Meson build system
Version: 0.56.2
Source dir: /home/superkuh/app_installs/gamescope
Build dir: /home/superkuh/app_installs/gamescope/build
Build type: native build
meson.build:1:0: ERROR: Meson version is 0.56.2 but project requires >=0.58.0
So I looked for other, less involved options. Brute forcing it with xdotool was my first thought. Another I found was https://github.com/QQuark/WGrab which is very simple but it involves manually setting the window span with the mouse each time. So I went with xdotool. This 24 line perl script completely solved my problem. And it's video card agnostic, unlike gamescope which only works with amdgpu.
#!/usr/bin/perl
use strict;
use warnings;
my $X_MIN = 0;
my $X_MAX = 1919; # 1920px
my $Y_MIN = 0;
my $Y_MAX = 1079; # 1080px
while (1) {
my $loc = `xdotool getmouselocation`;
my ($x) = $loc =~ /x:(\d+)/;
my ($y) = $loc =~ /y:(\d+)/;
my $nx = $x < $X_MIN ? $X_MIN : ($x > $X_MAX ? $X_MAX : $x);
my $ny = $y < $Y_MIN ? $Y_MIN : ($y > $Y_MAX ? $Y_MAX : $y);
if ($nx != $x || $ny != $y) {
system("xdotool mousemove $nx $ny");
}
select(undef, undef, undef, 0.02); # 20ms polling
}
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
superkuh on blog at (photoblog post, non-rss feed)
Another solar heated hot air balloon made of thin plastic drop cloth with the inside coated in "air float charcoal" to make it absorb light better. Folded out of a sheet 24ft*50ft in size made from 2x 12ft*50ft sheets taped together with wide clear packaging tape.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I developed vramgaze (for amdgpu) on a kernel 5.x machine. 5.x kernels expose per-region VRAM allocation data because amdgpu_vram_mm used the old drm_mm allocator which dumped every individual used/free node. On kernel 6.1, the amdgpu driver switched to the buddy allocator which only reports summary statistics. This means vramgaze can't see the VRAM regions/blocks and it just sees one big block; no hints where interesting stuff might be or what PID owns that range. This made using vramgaze on my 6.x boxes less fun and less useful.
The 6.x amdgpu driver does not export this information in any form. The only possible solution was to re-implement the kernel 5.x feature using a custom kernel module written for 6.x kernels. After hard freezing and crashing my test 6.x box a dozen times during development I finally have a custom kernel module, vramgaze_buddy, which restores the lost functionality. When loaded and runnning it reconstructs the per-node allocation map of the AMD GPU VRAM buddy allocator (drm_buddy) and exposes it as a human-readable debugfs seq_file (/sys/kernel/debug/vramgaze_buddy_nodes). This replicates the flat per-block view that existed in 5.x's drm_mm interface.
vramgaze-gtk3-kernelbuddy.pl has been altered to use this kernel module's interface at /sys/kernel/debug/vramgaze_buddy_nodes to fill in the gaps if it's available. So now vramgaze *can* work the same way on linux 6.x machines. Yay. The new version also works fine without the kernel module loaded on 5.x systems. And it'll work without the kernel module on 6.x but not give as much information. This new version also includes a few other unrelated bug fixes for automatically finding the right DRI and new features like an explicit BO map.
Now I know no one is going to want to run a random *vibe coded* kernel module. Doing vibe coded stuff in userspace is bad enough. But I'm putting it up here for those unlikely adventurous souls with linux kernel 6.x and a desire to view their amdgpu's VRAM.
To compile it the 'Makefile' is simple (and also included as a comment in the vramgaze_buddy.c source code).
obj-m += vramgaze_buddy.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
Once that text is in the 'Makefile' file in the dir with vramgaze_buddy.c you can build it and load it like,
last update: 2026-04-28: fixing DRI parsing, kernel 5 vs 6 amdgpu_vram_mm format differences
I was having an issue with mouse cursor icon getting corrupted but only on the 2nd monitor in a dual monitor system. I wanted to look at the VRAM representation of the icon. It turns out looking at GPU RAM is a lot harder than system RAM. And basically only modern amdgpu based systems allow it and that through /sys/kernel/debug/dri/*/amdgpu_vram. The region meta-data is from amdgpu_vram_mm in the same debugfs directory. It seems like doing this kind of thing is flat out impossible on nvidia. Any attempt at direct PCIe access or using BAR windows (which are static in position and small) I could not get to work. If anyone out there knows how to read raw vram from nvidia cards I'd love to hear about it. Lucky for me my system was using an AMD RX 580 8GB on amdgpu.
After a day or two of vibe coding, manual fixing, and passing back and forth between claude, gemini, and kimi-k2.5 and feeding in memgaze.pl examples I ended up with a fairly usable gtk2 vramgaze.pl. I did everything in gtk2 first because that's where I'm comfortable but because this seemed like something others might use I did port to Gtk3 too. They're pretty much the same but Gtk3 required some bending over backwards for cairo use.
I didn't actually find it useful for the cursor problem but it's a lot of fun watching VRAM get allocated and get fragmented under pressure and the like. The actual data in VRAM, which I expected to be full of bit maps (like framebuffers) and the like instead is all... encoded. I haven't seen a single bit of bitmap looking thing at all. It still makes for fun electronic music when interpreted as 8 bit unsigned wav audio.
*edit, later*: I actually did find where firefox was storing it's images in the GPU VRAM. Here you can see youtube thumbnails.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I still assume I'm the only user of the software "I" make (vibecode) but here's a set of updates.
connmapperl - I finally updated the release .tar.gz and docs to the version I've been using which shows all connection colors at a specific GPS coordinate even if they're stacked on top of each other; triggered on mouse-over or with a key 'g' based toggle. connmapperl.tar.gz (90MB)
feeed.pl page - "I" finally fixed the UI blocking freezes that happened during updating many hundreds of feeds at once by making feeed.pl (160KB) multi-threaded.
libre.fm music scrobbler - "I" vibe coded a new audacious 2.x plugin for music scrobbling to libre.fm last week. Mostly because I couldn't figure out why the ancient one wasn't working. It wasn't working because the libre.fm dude put it behind cloudflare who's IPs I have all blocked. But whatever, now I have the easily debugged and working, librefm-scrobbler.c.
festival 1.96 on modern distros - I struggled to get Festival 1.96 (an ancient codebase) working on modern linuxes (anything past ~2010) for more than a decade. But finally with the help of some LLM AIs "I" figured it out. At the end of the LLM debug session I had the LLM AI generate a bash script to automate the process of downloading festival 1.96 files, the nitech voices I mirrored on my public webserver (this one), the unpacking, moving, and compiling of them to allow the production of a Festival 1.96 + Nitech HTS voices all-in-one .deb file for Debian 12 and 13. I've tested it on a handful of machines and it works reliably. It'll probably work on other Debian distros and Debian derived distros. This is a big deal for me because it was the main feature holding me back from using a modern distro as my main.
In non-software news I've been back the project to grow pyroelectric crystals for use in particle acceleration. I've built simple PID module + temp probe water bath that can maintain it stably enough. But the big thing that re-ignited my interest was a new way of growing large seed crystals with easily identifiable crystallographic faces *without* temperature control. The trick is to grow the crystals within a gel.
Growing crystals within a gel apparently provides nucleation sites that have almost zero currents, not even significant diffusion, and the crystal seeds that grow and form within the gel express their innate crystallagraphic shapes rather than dendritic or twinned or messy crystals. For triglycine sulfate which is strongly acidic a normal basic-only gelatins doesn't work but sodium metasilicate "water glass" gels do work. The process is to grow and set the gel, then pour the TGS solution on top and let it seep down into the gel where it forms the proper seed crystals. I imagine it'll be a battle to preven crystallization from the hydrophobic creep up the sides of the gel container above the gel but I guess as long as I keep the solution topped off this doesn't matter too much.
For this project I've been learning to scribe and cut glass. And boy am I bad at it. Most of the time there's some nubbin or projection left and usually a crack within the wanted glass. I guess if you're a flameworker and glassblowing these things just kind of even out but if you're using the glass as is... it's a lot of rotary tool work and glass dust.
# triglycine sulfate solution
30.6 g Glycine (0.408 mol 3 parts)
29.7 mL Battery H2SO4 (SG 1.265, 35.5%) (0.136 mol 1 part)
0.95 g L-alanine (0.0107 mol 7 mol% of TGS)
84.5 mL Distilled water
# Sodium silicate gel
12.2g Sodium silicate solution (41%)
42.8 mL Distilled water
Battery H2SO4 (SG 1.265, 35.5%) pre-diluted 1:10 titrated to pH 3.0-3.5
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Getting sound working on an Asus Chromebook C423N (codename: RABBID) is hard. It took me 2 weeks and probably a dozen hours of trial and error. The normal chromebook sound fix scripts by Wierdtree at chromebook-linux-audio will give you very threatening warnings if you try to use them with this hardware. And of course they don't work.
# This script configures audio (speakers and microphone) for Asus Chromebook C423N (RABBID)
# with Apollo Lake chipset, DA7219 codec, and MAX98357A amplifier.
# Using the ALSA + pulseaudio software stack with intel-sof audio drivers.
# ** THIS SCRIPT CREATES AND INSTALLS A SERVICE SCRIPT TO RESTART PULSEAUDIO 12s AFTER DESKTOP LOGIN FOR REASONS OF TIMING BEING HARD **
# ** ~/.config/systemd/user/rabbid-audio-user.service - calls rabbid-audio-fix.sh restarts pulseaudio
# ** You might not like the unintended consequences of that.
# ** I personally have no problems beyond the *ding* of new audio devices being found each boot.
# The other files it creates are:
/usr/local/bin/rabbid-audio-fix.sh - bring up the kernel modules in the right order with pauses, unmutes
/etc/systemd/system/rabbid-audio-fix.service - actually calls rabbid-audio-fix.sh
/etc/pulse/default.pa.d/rabbid-audio.pa - sets the RABBID specific audio hardware id paths as pulse input/output devices
/lib/firmware/intel/sof-tplg/ - INSTALLS, contents replaced, contains: sof-apl-da7219.tplg topology
/lib/firmware/intel/sof/* - INSTALLS, contents replaced, contains: sof firmware
/etc/modprobe.d/inteldsp.conf - points kernel snd module at ./intel/sof/ firmware forcing SOF driver for Apollo Lake audio
It uses the apt repos to install various needed packages. Then it downloads the currently newest build of the intel firmware and topology files, puts them in their appropriate debian-alike place, creates a .conf that points the kernel snd module at them, then two systemd services are created. One calls a script that brings up the kernel modules in a specific order with pauses between and then unmutes the created alsa devices and saves the alsaconf. An earlier created pulseaudio configuration uses hard coded RABBID-specific ALSA hardware device addresses for pulseaudio input and output devices then unmutes the newly created devices. Then the second systemd service script restarts the entire pulseaudio service 12 seconds after the desktop environment boots in. Because I couldn't find a more reliable way.
User beware with the script. It does seem to just work and continue to work on reboot for I think the best way to use it is as a guide; going through and doing it manually line by line.
Do not try to use RABBID or other chromebooks with windows. The only audio drivers are *paid* and sold by an operation called "coolstar". But if you pay the small amount like I did to buy them you find out it's no longer in operation. The coolstar patreon just takes one's money while their backend system is broken and the drivers are inaccessible for download.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I was experiencing a weird slowdown and throttling between me and all of my VPSes at multiple different companies when doing specifically ssh transfers like rsync. Other protocols weren't getting throttled to 200KB/s but rsync was. I still have no idea why this happened.
When I looked back at the slow transfer it seemed like the time estimated remaining hadn't changed at all in 10 minutes. It felt like the rate was slowing down so the time remaining was always remaining the same. I thought that would be a funny thing to intentionally do. So I asked claude 4.5 to make it. And it works and it's kind of funny.
This vibe coded multi-threaded directory-listing python webserver will automatically reduce the data send rate so that it tries to keep the estimated time remaining at 60s. When the download first starts it kind of overshoots but if the file is large enough, or the upload speed of the line slow enough, it'll stabilize around 60s. Then as the rate tapers off to mere hundreds of bytes per second browsers will start overestimating the time remaining.
But the file download will never actually finish. It'll just get slower and slower and slower for hours and hours. It reminds me of the experience of dial-up file downloading in the 90s. Or as someone as described, the behavior of a live-caching proxy when that sends out the finished part of a file fast then slows down suddenly when it reaches parts which aren't finished yet.
It is a very silly joke webserver but I'm having fun with it. And the idea might be somewhat useful as a bot tarpit if you have the router/edge hardware to handle lots and lots of open tcp connections.
By default it binds to port 8000 on all interfaces. The port and target "time remaining" are just hard coded as 'port = 8000' and 'TARGET_TIME_REMAINING = 60.0'.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Someone recently pointed out to me that much of what memgaze is has already been done, and better. True, and if I could've remembered the ghidra's name I think I would've tried to use it with the digraph plugin. But ghidra is very complex and heavy to set up. What it, and it's sources, are good for is good ideas! It's full of them. Particularly a form of binary visualization and identification using "digraphs" from Voyage of a Reverser_A Visual Study of Binary Species_ Sergey Bratus_ Greg Conti_ BlackHat USA_ 2010.pdf. To quote them,
A digraph is when bytes in the binary data are considered in sequential pairs. So that for the binary data of the ascii text "black hat" it would be,
bl (98,108)
la (108,97)
ac (97,99)
ck (99,107)
k_ (107,32)
_h (32,104)
ha (104,97)
at (97,116)
Or the ascii string "battelle" would be,
ba (0x62, 0x61)
at (0x61, 0x74)
tt (0x74, 0x74)
te (0x74, 0x65)
el (0x65, 0x6c)
ll (0x6c, 0x6c)
le (0x6c, 0x65)
I basically just vibe coded this into memgaze 'image' mode and the result was instantly useful. The pairs of numbers (from the sequential byte pairs) are considered coordinates of pixels in an image object 256*256 in size and plotted as green pixels on a black background. But I noticed that detail was missing when I used *lots* of data so I added a 'normalized' mode too. I think it's pretty cool and both normal and normalized mode show different aspects.
Mouse hover over the example digraph images below for the process name and which part of memory is represented. The 8bit wav is really distinctive. Images always have arcs or continuous curved lines. Text is always boxy arrays. It becomes quite easy to identify data types just by eye. It's probably be fairly feasible to train a small visual model to do this automagically with a synthetic dataset of labeled binary data types and normalized digraph images.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I subscribe to a lot of feeds. About 1800 I've been gathering every day since I realized aggregation sites where on the way out in the early 2010s. I've been using QuiteRSS for about a decade to skim and read these feeds. It's a solid program based on sqlite. It mostly works. Every now and then the db grows out of control and external sqlite tools have to be used to vacuum back to size. But it gets almost all feeds, displays them all properly with HTML rendering and everything looks nice. Unfortunately with 1800+ feeds it's both a bit slow to switch between feed directories (after they're ~10k-100k feed entries in each) and I don't want to prune more often using it's tools because it's *slow* and tedious. It also uses a *lot* of ram, 1500MB rss.
Since we live in a world where we can just describe applications and debug them into existence I decided to try making my own feed reader. One that would be slim on RAM and performant even with tens of thousands of entries. I'd do this by only ever dealing with text. No HTML rendering. Just the best text interpretation possible. I don't know if I've succeeded. It certainly uses very little RAM. It's ~100MB rss. So far I only have ~thousands of entries in each directory but it is so snappy as to not be noticible. Text render is acceptable, there's some utf8 issues, some encoding issues, but everything is very readable.
Where feeed.pl really shines is in loading your .opml feed list and then figuring out which ones are broken and providing the tools to quickly fix it. The right-click context menu 'run test' provides detailed http header, request, and reply information as well as multiple alternative feed parsing regexs to figure out why a feed might not parse despite replying to an HTTP request. For truly broken feeds (bad domain, 503, permanently moved, etc) that are automatically detected and marked the right-click context menu 'search4feeds' uses a list of common feed names and mixes up site domain, dir, and subdomains to try to find common feed URL patterns for feeds that might have moved due to a change in content management system or the like. feeed.pl also keeps a copy of all http responses on disk in raw form for debugging which can be viewed with 'view source' right clicking on a feed.
And File->Check/Fix Broken... does what is shown in this screenshot. It exclusively tries all marked broken feeds once more, then attempts to guess feeds URLs and changes the light to green if there is one. Feedburner gives lots of false positives.
It's a lot easier to find and fix broken feeds in feeed.pl than it is in QuiteRSS. And for quick skimming of news that doesn't need all the HTML rendered glory and utility it does as a main feed reader.
But since I made this to scratch my own itch I didn't really bother with max ease of install. I use a lot of not normally installed by default perl libraries like AnyEvent, AnyEvent::HTTP, XML::LibXML, and use XML::Feed (which are backed up by many layers of regex fallbacks) and SQLite via DBI. So for a Debian alike, 'libanyevent-perl libanyevent-http-perl libasync-interrupt-perl libguard-perl libdbi-perl libdbd-sqlite3-perl'. Among others I probably missed because my machines all have so many perl libs installed manually.
I doubt anyone wants it, but, here's feeed.pl (136KB)
It creates a new directory in ~/.config/ by default called ~/.config/feeed/. Within ./feeed/ are the feeds.sqlite feed data db, ./feed/.feeedconfig which is a Storable hash dump of the feeed.pl configuration options, and the directory ./feeed/feeds/ which contains all the folders you create or imported from the .opml and within those subfolders are the raw HTTP responses from the feed URLs. Also temporarily in ./feeed/ during program execution are the temp files feeds.sqlite-wal and feeds.sqlite-shm.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Google has begun requiring all software on their Android ecosystem smartphones to be cryptographically signed with a cert they generate after the particular developer gives them money and doxes themselves in future leaks, or government requests, of their ID and other information. There's no opt out. This is all Android certified smart phones and all applications. Users won't be allowed to install their own applications any more.
And now people are debating the practicalities along with the ethics. But the law and ToS acting like law have been made clear.
Smart phones are not general purpose computers. They are not owned by the end user and cannot be owned by them at multiple layers in the stack: from the PHY baseband computer and radio transmit licensing, to the lack of root, memory access lockdown, applications that refuse to run without corporate certs, and even development of software now. HTTP/3, openwashed through the IETF by Google/MS, is also entirely mobile-centric and doesn't even work without a corporate CA for TLS.
I don't think there's any coming back from this given what smartphones are used for and how people are.
Because of this we, people who use computers for computer things, need to stop trying to compute on smart phones. I know that's a rough pill to swallow. But that's just the legal and practical reality that intrudes into day to day use more and more. They aren't computers and you won't be allowed to use them as computers. What they are is amazing bank dumb terminals, navigation and communication systems, and hot spots for using real general purpose computers that you can and do own.
And once geeks stop using the platform for computing, stop developing cool things for it to scratch their own itches either because they aren't allowed or don't use the platform anymore, all that will be left is the kind of software people would only make if forced to in exchange for income. And eventually, maybe... people will chose to start using real computers again just because they're fun. Computing should be fun. But that's probably too optimistic.
What is certain is that fun software is incompatible with smartphones. So recently Apple decided that the user shouldn't be able to even look inside their own computer with: Memory Integrity Enforcement
This is the opposite of fun computing. It's literally the bad guy from Apple's "1984" commercial. This is computing who's only use case is making sure that people can send/receive money through their computers securely. A needed device but it makes for a terrible, terrible computer.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
This is another release of connmapperl with the client to server connections now using SSL encryption now instead of plain plain data structs sent over the wire. The SQLite Query Interface results can now be replotted back onto the world map. It also has an icon. But mainly it's the SSL stuff that makes this update useful. I was starting to feel uneasy about streaming all my various computers' connection data in plain text over the internet.
You can either use the pre-generated server-cert.pem and server-key.pem, or better, delete them, then run the connmapperl-server.pl program again and it will autogenerate new ones by calling openssl. server-cert.pem has to be in the same directory as the connmapperl-client.pl on remote machines for it to connect! Just TLS things.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
memgaze-pdl.pl (118KB, requires libperl-gtk2, PDL, and 'aplay' binary for sound)
This is another release of memgaze but with a bunch of quality of life fixes and a few new features like the tools for better extracting specific images and algorithmically solving for their likely original image widths.
This algorithm is based it on the idea that while manually adjusting the horizontal image width with a slider I'd see how there'd be diagonal lines (aliasing?) formed whenever the horizontal width wasn't just right (or some harmonic multiple of right). If it was right then the pixel at X position 89 in one line would likely be the same or similar to pixel at X position 89 in the line below it. Vertical lines. Only when it was the right width would the slanted lines disappear. Telling this to gemini-2.5-pro resulted in the code to do it.
It steps through a large range of tested horizontal resolutions and for each it compares vertically adjacent pairs of lines in the image to see how different they are. Specifically it does line_n - line_n+1 = score and takes the absolute value of [score] for all line pairs in an image summed together as the real score for that test width. The lower the score, the more the two adjacent lines are very close to the same, the more likely it is that that's the right resolution without wrapping or aliasing. So it goes through and computes the net score for each resolution and then reports the one with the lowest as the likely horizontal resolution and sets the image object to display it.
This usually works. If there's no real order in the data it'll often have a bias for settling on lower horizontal resolutions rather than higher. But for actual image data it will at least settle on an alias of the image from which you can figure out (based on overlaping/mirror repetition) to go higher or lower manually to find the true width. And if the image representation in ram has blank lines between actual lines this only find harmonic multiples of the true resolution.
sub calculate_vertical_coherence_fast {
my ($pixels, $width, $height, $step) = @_;
my $rowstride = $width * 3;
my $total_difference = 0;
# Iterate with a step for both x and y to sample the image
for (my $y = 0; $y < $height - $step; $y += $step) {
for (my $x = 0; $x < $width; $x += $step) {
my $offset1 = ($y * $rowstride) + ($x * 3);
my ($r1, $g1, $b1) = unpack('CCC', substr($pixels, $offset1, 3));
# Compare with the pixel $step rows below
my $offset2 = (($y + $step) * $rowstride) + ($x * 3);
my ($r2, $g2, $b2) = unpack('CCC', substr($pixels, $offset2, 3));
$total_difference += abs($r1 - $r2) + abs($g1 - $g2) + abs($b1 - $b2);
}
}
return $total_difference;
}
In native perl these many comparisons were kind of slow. So I asked gemini-2.5-pro for help (again) and it made a really clever PDL (perl data language, compiled c/fortran internals for fast operations) version that at least 10x as fast as the cost of slightly increased RAM usage for memgaze.pl. With PDL piddle objects nothing is ever really copied or moved. Instead PDL creates different "views" of the same object and this is much faster.
for my $test_width ( $min_width_to_test .. $max_width_to_test ) {
...
my $trimmed_size = $test_width * $test_height * 3;
my $image_pdl = $pdl_data->slice("0:" . ($trimmed_size - 1));
my $reshaped = $image_pdl->reshape(3 * $test_width, $test_height);
my $top_rows = $reshaped->slice(":,0:-2");
my $bottom_rows = $reshaped->slice(":,1:-1");
my $score = sum(abs($top_rows - $bottom_rows));
my $normalized_score = $score / $test_height;
...
if ($lowest_score == -1 or $normalized_score < $lowest_score) {
$lowest_score = $normalized_score;
$best_width = $test_width;
}
}
$top_rows is one of those "views". It includes all columns (:) but only rows from the first (0) up to, but not including, the last (-2). For a 1920 px wide test that'd be rows 0 through 1919. $bottom_rows is a view that includes all columns (:) but only rows from the second (1) up to the very end (-1). So that'd be rows 1 to 1920. That's two arrays of the exact same dimensions perfectly aligned so that row n in $top_rows corresponds to the original row n, and row n in $bottom_rows corresponds to the original row n+1. So when $top_rows - $bottom_rows it subtracts the entire bottom_rows array from the top_rows array, element by element, all at once in highly optimized C code. The result is a new piddle of the same size containing all the differences for taking the absolute value and sum.
Another problem for me personally writing the thing was that as soon as I use PDL;'d it overloaded a lot of the CORE:: perl functions like index() and suddenly my 'Process' list search button stopped working and giving wild errors with line numbers that didn't match to the code it was talking about. And at the time I had no idea that use PDL; overloaded/replaced functions like this. I spent a half day trying to figure it out before eventually someone on IRC mentioned PDL did this and I realized that index() had been replaced with PDL::index(). Changing all my index and related to CORE::index fixed it but I'd never have figured this out on my own. It stumped gemini-2.5-pro too.
while (defined $search_iter) {
my $display_text = lc($model->get($search_iter, 0));
# use CORE::index to avoid conflict with PDL::index
if (CORE::index($display_text, $search_text) != -1) {
$selection->select_iter($search_iter);
my $path = $model->get_path($search_iter);
$proc_tree_view->scroll_to_cell($path, undef, FALSE, 0, 0);
return; # Found a match, we're done.
}
$search_iter = $model->iter_next($search_iter);
}
p.s. the funnest feature in this new version is wildly moving the image width slider around and seeing the aliasing "animate".
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
One day I decided I wanted to be able to "see" what was going on inside the RAM in my linux desktop computer. And now through the magic of LLM AIs and some time, debugging, and tweaks, I can. I haven't ported it to gtk3 yet so it's gtk2 only for now.
memgaze.pl (94KB, requires libperl-gtk2 and 'aplay' binary for sound)
memgaze is a linux process virtual RAM exploration tool. It creates visualizations as images of the *virtual* RAM of any accessible process (run with sudo) and can save them as PNG. It also can play any RAM dump or subsection(s) of it as a sound file or save to wav. It has tool-tip overlays that show what type of RAM allocation it is and what, if any file it's associated with on disk (or heap or stack or anonymous) on both the hilbert map and image map.
To make the image memgaze walks through massive strings of ram dump bytes, taking them three at a time to form each pixel. Each byte has a value from 0 to 255. Coincidentally each color channel in a standard 24-bit RGB pixel is also represented by a value from 0 (no intensity) to 255 (full intensity). This allows for a 1-to-1 mapping.
The 1st byte becomes the Red component of the first pixel.
The 2nd byte becomes the Green component of the first pixel.
The 3rd byte becomes the Blue component of the first pixel.
The 4th byte becomes the Red component of the second pixel.
The 5th byte becomes the Green component of the second pixel.
And so on...
You might think this would lead to inconsistent coloring just because something shifts by one byte but it's not. The same libraries always look the same way when loaded in ram and visualized this way. Even between reboots and across different computers. And with time I'm starting to see how different types of RAM allocations have different types of textures. The data really does speak for itself.
For generating sound it's different.
But first a diversion: I've found some really interesting sounds in various programs. I really like libgtk-3.so it has some nice bass. Here's some musical tracks that I selected as truly "computer generated" music. Listen to this while you read how it works.
The stream of bytes from memory is a sequence of points that define a sound wave. Each byte's value is interpreted as the amplitude (loudness or position) of the sound wave at a single, tiny moment in time.
Unlike the image which groups bytes into threes, the sound translation treats every single byte individually. For sound the RAM dump is interpreted as unsigned 8 bit values and each byte is treated as an unsigned integer from 0 to 255. This number represents the position of the speaker cone at one instant. A value of 128 is considered the "center" or silent position. A value of 255 tells the speaker to push all the way out. A value of 0 tells the speaker to pull all the way in.
A sequence of bytes like 128, 150, 200, 255, 200, 150, 128, 100, 50, 0, 50, 100, 128... would create a simple smooth oscillation (a pure tone).
For example a snippet of memory containing the ASCII string "Hello..." followed by some binary data.
Hex Value Decimal Value Interpretation as Sound Amplitude
0x48 72 Speaker cone is pulled in from center.
0x65 101 Speaker cone is still pulled in, but closer to center.
0x6C 108 Getting even closer to center.
0x6C 108 No change from the last sample.
0x6F 111 Still pulled in.
0x00 0 Speaker cone pulls all the way in (max negative).
0xFF 255 Speaker cone pushes all the way out (max positive).
0x7F 127 Almost perfectly centered (nearly silent)
When played back at 8,000 bytes per second (8 KHz sample rate), this sequence creates a series of rapid clicks and pops. The relatively smooth values of the "Hello" string would sound like a low, static-like rumble. The sudden jump from 0x00 (0) to 0xFF (255) would produce a very sharp "click" or "pop" because it's telling the speaker to move from its most retracted position to its most extended position in just 1/8000th of a second.
To get a birds eye view of the virtual ram system it maps all used virtual ram onto a space filling hilbert curve with selectable sub-section and tool-tips showing the proportional use of virtual RAM by every process. Right click any highlighted process on the map to 'Image' it's RAM in a new window. To be clear, this is virtual RAM mappings, and the numbers it gives are not useful when you're trying to figure out the physical amount of RAM any given process is using (though it is proportional).
On the image map there's a small "thumbnail" view for zipping around truly gigantic ram dump images for convenience on slower machines. The image of the RAM can animate it live at the user supplied rate (default every 1s) but this only really works with small amounts of RAM because refreshing big GB amounts takes time. When the RAM is 'Updating' the state it was when the 'Update' button was pressed is stored to compare against the final state when updating is done with the 'Diff' tool which turns green when there's an old version to diff against. The 'Strings' tool runs $ strings against the full RAM image or whatever set of offset selections are checkbox marked active and then marks them on the RAM image with a star and recenters the view on this location and displays all matches with their file offset in the text box. Deleting the search string and hitting enter on the empty box restores the raw strings output list.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I've been puttering away at improving my connmapperl port(s) of connmap (c/X11) geoip map network visualizer in terms of both features and performance. ip2asn.pl for the fully-offline(local) asn and org-name and peering look-ups is ever so slightly faster. The sql database side for long term detailed connection history is about 10x faster and 100x less IO which shows how bad it was before stateful connection tracking. Fancy things like sql queries and a mapping of the points onto the ipv4 range on a space filling hilbert curve (like the xkcd comic) also exist. The client program is forwards and backwards compatible; it just handles sudden socket closings a bit better, re: reconnecting now.
The size is from the included geoip dbs and regional internet registry whois dumps. Leave the .pl files in the extracted folder and just run them there.
All this started with and was forked and ported from an inspiringly simple .c program for X11 called connmap. My versions just happens to be in another language and graphical toolkit and tacks on sql points history and a lot of not necessarily useful features and eye candy. I still don't understand the original connmap's math for the lat/lon gps to x/y pixel translation but luckily through open source licensing I can build with it.
connmap-(tk|gtk2|gtk3) and [connmapperl-server + connmapperl-client] are a set of geoip map visualization applications. They rapidly call 'ss' and 'lsof' for established tcp connections and shows geoip dots, program process name, ASN, and Org Name where the remote peer is. They also can right click on points to pop up a window with copyable-text and a form for doing offline whois look-ups. It does this only accessing database files stored on disk. No network calls or getting banned by whois servers. It was made with lots of gemini-2.5-pro LLM AI help.
The size is from the included geoip dbs and regional internet registry whois dumps. Leave the .pl files in the extracted folder and just run them there.
The above are my simple ports and expanded forks from C to Perl of the X11 program connmap.
I did this because my Ubuntu 10.04 computer with Xorg 1.7 was too
old to run the original connmap program. At least 1 of these 5 programs
will run on almost anything from 1998 to 2025.
But as I did it I was having lots of fun so I added new obvious features and eventually diverged quite far from the base connmap code. Except in terms of lat,long to x,y calculation and the core concept; the hard stuff. That is still the same wonderful connmap logic.
"connmap-tk", "connmap-gtk2", "connmap-gtk3", and "connmapperl-server" have some extra features but don't
have the ability to scale like connmap. "connmap-simple-gtk3" is a pure port with no extra features that
can't scale like connmap either. None support "connmaprc" and instead use "connmapperlrc"; a new format.
"connmap-gtk2", "connmapperl-server", and "connmap-gtk3" are the best versions (though sometimes -gtk3 lags behind in features). They all load local/peer port map/color rules from config files which can be toggled on/off in the program by clicking the square buttons next to their name in the color key. They save all geoip points history, toggle with 'h' key, and can overlay them as white transparent circles scaled proportional to the number of times they appeared. They can save 's' and load 'l' this history file from disk. They can turn off global ip->asn/org-name look-ups and display globally by pressing 't'. They can right click near points and get a detailed list of their info as well as a field for doing full off-line whois lookups.
"connmap-simple-gtk3" is a direct port of connmap. No extra features. "connmap-tk" is somewhere in between.
"connmapperl-server" and "connmapperl-client" are the same program as "connmap-gtk2" but split into a gtk2 server/GUI and lightweight cli daemon clients which connect over the network via tcp/ip. It's really neat seeing all my computers and my VPSs active internet connections on one map at the same time on my home desktop. Since the client is pure perl and core modules only it runs on anything that has linux's "ss" and "lsof" programs.
Feature comparisons and Non-core Perl Dependencies
--- client/server architecture ---
"connmapperl-server" is a windowless GUI program server that listens on a port for client data and displays.
listens on port 6789
visual updates a tiny bit slower (1s), but client->server data updates are still fast (0.1s).
uses Gtk2 (which rocks) which your modern OS probably doesn't have.
can be dragged around with the mouse left-click hold.
has right-click map to get list of points IPv4 info within circle near the mouse pointer.
- optional ip2asn non-network based fully offline whois lookups for right click menu
has 't' key toggle for doing the 'text' ASN/Org-Name look-ups and showing them.
has 'h' key toggle for 'history' which shows all points seen scaled by count.
has 's' and 'l' keys to 'save' and 'load' history points.
has 'Esc' key to close and also an invisible exit button in the top right.
loads ports/colors/names from config file "connmapperlrc"
- does search/shows text depending on local/peer and port in "connmapperlrc"
- can turn look-ups for rules on/off by clicking square next to their name in the key.
- has 'c' config key to reload connmapperlrc file settings while running.
Perl Dependencies: use Gtk2, use Cairo, use Glib, use Net::IP, use Text::CSV
"connmapperl-client" is a tiny perl core modules only script that will run on everything, even routers.
is headless and uses a tcp connection to connect to connmapperl-server
requires the presence of $ ss and $ lsof binaries.
connects to port 6789
Perl Dependencies: none
--- single program architecture ---
"connmap-gtk2" is windowless and can be dragged around with the mouse left-click hold.
has right-click map to get list of points IPv4 info within circle near the mouse pointer.
- optional ip2asn non-network based fully offline whois lookups for right click menu
has 't' key toggle for doing the 'text' ASN/Org-Name look-ups and showing them.
has 'h' key toggle for 'history' which shows all points seen scaled by count.
has 's' and 'l' keys to 'save' and 'load' history points.
has 'Esc' key to close and also an invisible exit button in the top right.
uses Gtk2 (which rocks) which your modern OS probably doesn't have.
loads ports/colors/names from config file "connmapperlrc"
- does search/shows text depending on local/peer and port in "connmapperlrc"
- can turn look-ups for rules on/off by clicking square next to their name in the key.
Perl Dependencies: use Gtk2, use Cairo, use Glib, use Net::IP, use Text::CSV
"connmap-tk" has a traditional window bar.
hard coded: shows process name : port, ASN, and Org Name text for most ports
is Tk. Tk never changes and is available on both old and new OSes.
is Tk and so a little slower.
Perl Dependencies: use Tk, use Net::IP, use Text::CSV
"connmap-simple-gtk3" is a *direct* 1-to-1 connmap X11 feature port.
is a simple port that just shows red dots.
is what will run on most modern OSes.
is windowless and can be dragged around with the mouse.
Perl Dependencies: use Gtk3, use Cairo, use Glib
"connmap-gtk3" is windowless and can be dragged around with the mouse left-click hold.
has right-click map to get list of points IPv4 info within circle near the mouse pointer.
- optional ip2asn non-network based fully offline whois lookups for right click menu
has 't' key toggle for doing the 'text' ASN/Org-Name look-ups and showing them.
has 'h' key toggle for 'history' which shows all points seen scaled by count.
has 's' and 'l' keys to 'save' and 'load' history points.
has 'Esc' key to close and also an invisible exit button in the top right.
uses Gtk3 which is what will run on most modern OSes.
loads ports/colors/names from config file "connmapperlrc"
- does search/shows text depending on local/peer and port in "connmapperlrc"
- can turn look-ups for rules on/off by clicking square next to their name in the key.
Perl Dependencies: use Gtk3, use Cairo, use Glib, use Net::IP, use Text::CSV
The local/peer ports, their names, and their colors from a config file located in the same directory as it: connmapperlrc. These rules can be toggled for IP->ASN/Org-Name resolution and display by setting the last field to 0=Off or 1=On, or done so while the program is running by clicking their corresponding colored square in the key.
# connmapperlrc - Configuration for ConnMapperl
# Format: KeyLabel,Type,Port,Red,Green,Blue,Alpha,ShowText
# ShowText: 1 = Display dot and text, 0 = Display dot only
"Webserver",local,80,0.2,0.5,1,0.8,1
"Webserver",local,443,0.2,0.5,1,0.8,1
"Web Surfing",peer,80,0.68,0.85,1.0,0.8,0
"Web Surfing",peer,443,0.68,0.85,1.0,0.8,0
"IRC",peer,6667,1,1,0.2,0.8,0
"IRC",peer,6669,1,1,0.2,0.8,0
"IRC",peer,6660,1,1,0.2,0.8,0
"IRC",peer,5555,1,1,0.2,0.8,0
"SSH Out",peer,22,0.6,0.2,0.8,0.8,0
"SSH In",local,22,0.7,0.2,0.6,0.8,0
"IMAP/S",peer,993,0.1,0.9,0.2,0.8,0
"IMAP/S",local,993,0.1,0.9,0.2,0.8,0
"smtpd",local,587,0.3,0.6,0.3,0.8,0
"Torrents",local,12000,1.0,0.4,0.7,0.8,0
"Torrents",peer,12000,1.0,0.4,0.7,0.8,0
"Shadowsocks",peer,31415,0.5,0.5,0.5,0.8,0
"Shadowsocks",local,31415,0.5,0.5,0.5,0.8,0
"Shadowsocks",peer,31416,0.5,0.5,0.5,0.8,0
"Shadowsocks",local,31416,0.5,0.5,0.5,0.8,0
"connmap",local,6789,0.5,0.5,0.1,0.8,0
"connmap",peer,6789,0.5,0.5,0.1,0.8,0
# By default only connections to the local webserver are shown with ASN+OrgName lookups
# because that process is somewhat cpu and io intensive. This applies to the 'h' history
# function too. Points matching local or peer ports with ShowText field 0 will not show
# up as dots in history's scaled dot display.
# Generally anything that's always going that you already know about set ShowText 0 to
# ignore and not blow out the history heatmap.
Right-click the map to get a selectable text pop-up of IPs near the click. The white circle which appears briefly shows the range. Local whois/peering look-ups available in the pop-up window detail list.
There a lots of comments at the top of the source re: configuration required if any.
Paths are set relative to the folder so as long as ./resources/ exists
and you have the perl modules required it should work.
An aside on the lack of libgtk2-perl on many distros
There are a few tricks to getting it to work but the most important one is at the very top of the ./libgtk2-perl/debian/rules file (on a new line before any other text), adding the following line:
Without this it's all "xs/Gtk2.c: loadable library and perl binaries are mismatched (got handshake key 0xce00080, needed 0xed00080)" errors when Gtk2 is actually attempted to be used.
Otherwise it was just a matter of changing some paths and versions in the ./DEBIAN/control file of the libgtk2-perl_1.24993-1_amd64.deb produced after, "$ DEB_BUILD_OPTIONS=nocheck debuild -us -uc -b" like changing DEBIAN/control so that perlapi-5.28.1 -> perlapi-5.32.1, and changing the folder name of ./usr/lib/x86_64-linux-gnu/perl5/5.28 to ./usr/lib/x86_64-linux-gnu/perl5/5.32 (for Debian 11, for other distros use the appropriate perl version/path).
I did this by unpacking the produced .deb,
dpkg-deb -R libgtk2-perl_1.24993-1_amd64.deb tmp/
Then doing the above changes manually, then repacking,
dpkg-deb -b tmp libgtk2-perl_1.24993-1_GOODPATHSWORKING_amd64.deb
Then there's the command line tools I made for offline whois.
If connmap-gtk2.pl detects ip2asn.pl in the directory it will offer the option to use it for all local (no network connectivity needed) look-ups of whois dumps from the regional internet registries.
"ip2asn" is a sort of janky fully-local "whois" for all 5 regional internet registries.
The other scripts are for processing the raw data to a form usable for ip2asn.pl
It started as a scratch pad for testing which were the best ways to go from IP to
organization name but eventually became a useful tool in it's own right to avoid
getting throttled by internet whois servers when doing many lookups in a row.
It uses 4 diferent methods to try to go from IP to ASN and org name.
The first 3 methods are relatively fast.
The 4th, awk'ing through big whois dumps, is not.
It is called like: $ ./ip2asn 94.74.97.164
--- Found IP Information for: 94.74.97.164 ---
Registry: apnic
Country Code: SG
Start IP: 94.74.64.0
Range Size: 16384
Status: allocated
Opaque ID: A917E678
--- Associated ASN Records ---
HUAWEI INTERNATIONAL PTE. LTD.
ASN: 131444, Count: 1, Status: allocated, Date: 20160715
ASN: 136907, Count: 1, Status: allocated, Date: 20170807
ASN: 141180, Count: 1, Status: allocated, Date: 20200914
ASN: 149167, Count: 1, Status: allocated, Date: 20211206
ASN: 151610, Count: 1, Status: allocated, Date: 20230712
HUAWEI INTERNATIONAL PTE. LTD.
22.2908 , 114.1501136907 - "HUAWEI CLOUDS"
aut-num: AS131444
as-name: HIPL-AS-AP
descr: Huawei IT Data Center in AP
country: HK
remarks: --------------------------------------------------------
remarks: To report network abuse, please contact mnt-irt
remarks: For troubleshooting, please contact tech-c and admin-c
remarks: Report invalid contact via www.apnic.net/invalidcontact
remarks: --------------------------------------------------------
org: ORG-HIPL2-AP
admin-c: HIPL7-AP
tech-c: HIPL7-AP
abuse-c: AH905-AP
mnt-lower: MAINT-HIPL-SG
mnt-routes: MAINT-HIPL-SG
mnt-by: APNIC-HM
mnt-irt: IRT-HIPL-SG
last-modified: 2020-06-17T13:05:46Z
source: APNIC
It doesn't always work that nicely though. And lacnic entries are pretty bare.
All this is done by including 600 MB of RIR ipv4 delegation files,
all five regional internet registry's whois and peering dumps,
various maxmind geolite ip->lat,long csv databases, and
caida.org/archive/as2org/ as-org2info.txt. See appendix for URLs
Appendix of various resources and notes
### the various resources/* files and where they come from to update them.
## RIR whois/peering db
# RIPE NCC https://ftp.ripe.net/ripe/dbase/split/ripe.db.aut-num.gz
# ARIN https://ftp.arin.net/pub/rr/arin.db.gz
# APNIC https://ftp.apnic.net/apnic/whois/apnic.db.aut-num.gz
# LACNIC https://ftp.lacnic.net/lacnic/dbase/lacnic.db.gz
# AFRINIC https://ftp.afrinic.net/dbase/afrinic.db.gz
## RIR Delegation files
# https://www-public.telecom-sudparis.eu/~maigron/rir-stats/
# https://ftp.afrinic.net/pub/stats/afrinic/delegated-afrinic-extended-latest
# https://ftp.apnic.net/stats/apnic/delegated-apnic-extended-latest
# https://ftp.arin.net/pub/stats/arin/delegated-arin-extended-latest
# https://ftp.lacnic.net/pub/stats/lacnic/delegated-lacnic-extended-latest
# https://ftp.ripe.net/pub/stats/ripencc/delegated-ripencc-extended-latest
early version of the gtk2 port, what the gtk3 port looks like
recent version during a distributed botnet attempting to mirror the entire website at once
connmap-tk with integrating time lapse mode enabled by commenting out the "connection_item" tag on the dots:
# 1. Draw the dot using Tk::Canvas->createOval
$canvas->createOval(
$x - $radius, $y - $radius, $x + $radius, $y + $radius,
-fill => $dot_color,
-outline => $dot_color, # Use same color for outline to make a solid dot
# -tags => 'connection_item',
);
It's easy to see there is some error in the geoip placement on the map gif background.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
It is creating a problem, and fragmentation, for program configuration where none existed in exchange for the chance of a slight speed-up by keeping everything in ram. Setting this as a default in Debian 13 signals the Debians defaults are for *big* machines with excess ram. Users with smaller amounts will have to do a post install manual configuration to achieve normal performance and avoid slowdowns from tempfs taking ram and pushing things into swap when the ram inevitably fills. And the fallout from programs having to change their code just to avoid using /tmp for what it's meant for will be much larger.
Now you may say, "once there's memory pressure the tempfs will push back to disk anyway via swap" and that is true. But it is also true that the memory pressure wouldn't exist without the tempfs. And this pushing back and forth can only slow things down when compared to a more straightaway, less steps/io, setup of just files in folders on disk.
Another objection is "most people don't have much stored in /tmp". And that's also true. But that doesn't change the fact that /tmp is there to be used. It's meant for 5kb or 5GB. There has never been a limit. And now people are trying to say there must be a limit because of the bad downsides of this change.
That's not to say there are no upsides. The performance increase in some applications, like Firefox, is notable. Considering this, /tmp should be left alone and a new /tmpfs in ram "standard" be created for programs that desire the potential speed up. That way existing workflows would not be broken and devs would not have to change their programs code unless they wanted to.
In this context the "ram is there to be used" is a bad application of the meme, a bad default, and the /tmp->tempfs change resulting from it should be reverted in future Debian 13 point releases.
The good thing is that it's an easy fix for users (if not software devs): "You can return to /tmp being a regular directory by running systemctl mask tmp.mount as root and rebooting."
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
superkuh on blog at (photoblog post, non-rss feed)
This 30ft*12ft solar hot air balloon envelope made up of 5 gores was literally too big to handle with just one person. After this photo with 2 people I took it out by myself on a 8mph wind day and it ripped after fully inflating. I later managed to tape 4 of it's remaining gores back together.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I took this photo while testing my solar hot air balloon. It's much bigger than it looks from this angle. It's filled with air by hand then the sun heats it up and it rises. It's made by cutting off a 30ft * 12ft piece of 0.3 mil painter's plastic drop cloth ($30/300ft), folding it in half and sealing the remaining edges with clear packaging tape. The pillow shaped balloon then has one corner cut off and a cardboard mouth/ring put in for filling and the tether. The dark coloration is from air-float charcoal ($15 1lb) put inside and shook around till it coated the surfaces. These types of "free balloons" can lift a good fraction of a pound to over 60,000ft. But until I can understand and fulfill the FAR 101 regulatory requirements fully these are just brief handheld tests below local structure heights.
I learned how to make this type of balloon from the excellent documentation at Danny Bowman's Bovine Aerospace website and youtube videos.
The cardboard ring holding the balloon mouth open for inflation can be folded down onto itself a couple times to close the mouth and prevent wind from deflating the balloon. This folded cardboard block also provides a good place to wrap and knot the tether to the balloon. It's also fairly air-tight so a long flat tube casually rolled up as a pressure release valve might be necessary for non-tethered flight.
First lay out 30ft of the unfolded sheet. Then unfold it sideways and fold it vertically to make it two joined overlapping 15ft long sheets. Weight it down with random soft objects. Then go around the remaining 3 edges taping them together.
Now that I've figured out construction and everything works I'll move on to making a proper large envelope with normal diamond-like gores joined with strapping tape to distribute the load.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
superkuh on blog at (photoblog post, non-rss feed)
4-whistle.stl - whistles are the hello world of 3d modeling for 3d printing so I thought I'd try my hand to test my new printer. This '4 whistle' is 4 whistles all sharing the same mouth piece. 2 of of the same length and 2 are shorter or longer. So there are 2 whistles at the same tone beating against each other in sync and then two whistles at slightly different frequencies out of phase going in and out of beating interference.
It is not loud. Just blow softly. It sounds sort of like an old english police whistle.
20% infill and no supports at 0.2mm layers. ~1 hour. (Printables Page)
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
superkuh on blog at (photoblog post, non-rss feed)
3.5 cups bread flour, 1.25 cups water, 4 tsp salt, 1 tsp yeast, two periods of kneading a handful of hours apart. Boiled in salt water, washed, then added to broth. The broth is 4 tsp won-ton powder, 4 cups of water, a dash of sherry wine, 2 drops sesame oil, 1 tsp (lots!) of white pepper, 5 cilantro strands wrapped into a knot and soaked/removed, 1 jalapeano pepper split soaked and removed, 6 finely diced garlic gloves, and green onions garnish. The meat is pressure+slow cooked pulled pork in soy sauce/ginger/garlic/hoison sauce.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
superkuh on blog at (photoblog post, non-rss feed)
A 5 gallon bucket with holes in the bottom and sides and an towel attached with zip ties and folded underneath makes for a decent improvised zamboni for smoothing out the surface of rough ice out on the rink I maintain(ed) on the lake this year.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
IdleRPG is a game for internet relay chat where people join a channel and depending on how long they "idle" there without talking their "character" gets experience and levels. I've played the EsperNet idlerpg for 20+ years but this spring an esper staff member went missing and the network almost died. The chaos caused the idlerpg bot owner to stop running it but they did offer the database and config so others could run it. I now have it going on a VPS, hopefully for another decade or two.
IdleRPG has a feature where the player characters have specific locations on a 500x500 map. These maps are normally generated with .php scripts invoked by people visiting the .php web page. I re-wrote the quest map and world map generation scripts in perl and now run them once per minute and once per 15 minutes respectively via cron. There is no webserver tie in. All that is required is the perl, imagemagick's "convert", and the basemap.png. These two scripts are very simple but it did take me a bit to work out how to parse the irpg.db and translate the php'isms from the examples.
The maps below are the actual maps updating in real time.
*edit/update*: I also wrote a better questmap.pl that auto-generates a movie of quest progress too: [requires ffmpeg and imagemagick] questmap-ani.pl. It uses ffmpeg and adds a new directory achiving all quests as .mp4 files in addition to generating questmap.png like the original. Because I'm lazy the script doesn't actually know when a quest ends so it generates duplicates every hour. They're only ~300kB each but to keep things under control I run fdupes once an hour via cron which keeps only the first of any set of dupes.
There's a been a lot of talk about this article on predatory abuse of DMCA claims for censorship. To remove something from google's search they copy the text, they create a fake website / company with a URL with copied text then submit a DMCA claim saying theirs is the original. Google automatically rubberstamp approves it and the URL/text they want removed from the search index is removed.
There's a simple and easy solution: there should be "know your customer" for claimaints for laws requiring companies to follow up on legal claims like DMCA reports. KYC is obviously socially accepted and easily implemented since it's being required for so many other things. The whole basis of an adversarial legal system is that you need two legal persons on either side. This is a context in which you have to wonder why it isn't already like that.
Once false reports from fake companies and people are infeasible there will be much less of a problem.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
This one is a bit roundabout but stick with me. I've exchanged a few emails with the science.org website technical support people about the RSS feed for the excellent chemistry/pharmacology blog "In the Pipeline". It's not Derek's fault at all, but his science.org/aaas hosts have basically blocked native RSS feed readers and they only allow corporate service websites that do the feed reader part for you like Feedly.org. They consider using a native application feed reader to be scraping their website and ban them.
Hello $superkuhrealname,
I wanted to follow up on your inquiry regarding RSS readers being blocked on science.org. We allow most traditional RSS readers (like Feedly) but this one in particular (QuiteRSS) we do not support. It behaves differently than most readers by using a browser to scrape content similar to a bot. We encourage you to try another RSS feed reader.
Let me know if you have any questions. Thank you.
Jessica Redacted
Publishing Platform Manager
American Association for the Advancement of Science
1200 New York Ave NW, Washington, DC 20005
jredacted@aaas.org
All QuiteRSS does is literally an HTTP HEAD or GET for the feed URL.
It is the most normal of normal of RSS readers. So I'm a bit taken aback at how a professional organization can be holding such obviously ignorant and dangerous views about what an RSS feed is. I brought it up on a cyberpunk IRC channel and it was pointed out this reflects a more fundemental division in how computing is perceived these days.
this whole "scraper" equals the boogieman to people now. You're presenting data to an external client, what said client does with the data is none of your business.
You have people that saw the internet before it was commercial, or who know came later but know how the meat is made, that perceive it that way. Then you have commercial/institutional/government and people who were presented the web fait accompli who see it as a black box where interference is against the law; "interference" being a POV word choice. I don't think changing a CSS rule is interference but nowdays it'd be like vandalizing someone's building wall.
It's as if visiting a website and downloading the publicly available contents is a nation setting up an embassy of "foreign soil" on your hardware.
Their cultural expectation is that you cannot do what you want with that data. Modifying it or how it's displayed is, to them, is like walking into their business location and moving around the displays. So obviously the only legal interface is the one they provide "at their location" or via another incorporated entity they associate with. But of course they aren't at *their location* they're at my location on my property in my PC. But slowly this commercial norm is working it's way into leglistation to become our reality as web attestation.
What they see, and what they want, is a situation equal to you going to their business premise and sitting down at one of their machines. They want to own your computer in just the same way simply by you visiting a website. That shit's fucked.
Digging deeper into the situation I noticed the real problem: it's cloudflare. Of course. They're applying the cloudflare policies to the entire domain as whole and the invasive browser internals checks they have for bots are blocking everything other than major browsers and other corporations like feedly they add to whitelists. It was silly of me to expect their support email address to connect with a person who wouldn't ignorantly lie to me. The problem isn't DNS anymore. It's always cloudflare.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I've seen, and been part of, multiple heated conversations about the meaning of the phrase "static web site" is and what types of things it defines. For any communication I think we need to take as a premise that static HTML and static web sites are not the same category of thing. Any particular page on the web can be totally static or totally dynamic or a mix. There are static HTML pages on static web sites. There are dynamic HTML pages on static web sites. There are static HTML pages on dynamic web sites. And there are dynamic HTML pages on dynamic web sites.
The meaning of static HTML is the least contentious. A static HTML page is just an .html (or .htm, or anything else if the mimetype is set right) hypertext markup langage document that is stored on a file system as a file and sent to the end user when they request the URL that maps to that file. The HTML encodes what the web site user will see and does not change.
When the static .html file includes "static" (not really since it is executed code) javascript (or other executing language embeds) that changes the page to something other than displayed by the html in the file on disk. So it becomes a dynamic HTML page (for a while called "DHTML").
The only place where static HTML becomes unclear is in the case where some webserver linked program generates the static HTML on demand with no storage of the HTML as a file on the filesystem before being sent to the site user. In this case even though the user sees only static HTML there's crucially no file ever created on the webserver so it's dynamic HTML.
The meaning of static website is increasingly more unclear compounding on the fuzziness of what a static HTML page is. Generally there are the same two points of view as above but with a tweak.
There's the website users point of view where a static web site is static if the pages are just HTML and do not require executing any code to view. If you (or your browser) look at the source you can read the text and see the image URLs. It does not have to be generated by the browser's execution of some client side code.
Then there's the developer point of view where a static web site if the code required to generate the website is stored in a static file on the webserver. In this framing you can deploy a self contained .html file which includes the javascript code for a client side dynamic web application. This web application can completely change the text shown and even draw in outside information not in the file. But since it can be put on a CDN as a static asset it is a static web site.
I have to admit after writing this to clarify my thoughts I'm more confused than ever. The situation in which the end user only sees actual HTML in the browser but that HTML was generated without ever being a file on disk is definitely the case of a static HTML web page from the user POV. But it is also the most extreme case of a dynamic web site and everything bad about dynamic sites. Luckily this is the only exception to the rules that spoils the categorization. Maybe it's like the old saying says re: single exceptions.
This post HTML itself was written in gedit, then concatenated with a bunch of other .html files with a single line of shell and redirected to a file on the file system for the webserver to serve and scripts to process. The rss updates are generated by a single call to a perl script I manually type that scans the file system to generate the .rss file for the webserver to serve. Comments on this post will not be noticed by the webserver. But a perl script that tails the webserver access.log file on the file system will see them and then append the comment on to an existing .html file on disk.
Is this page a static HTML page? Yes. Is my site a static web site? I think so. Others would disagree.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I started outlining this scifi story about life on the sun back in 2010 when the first proposals for Advanced Technology Solar Telescope and Solar Probe were floated. But I never wrote the story and now the passing of time has caught up with the "future" I was writing about and it's not quite panning out. The discoveries about the magnetic switchbacks in the solar wind have been cool though. Anyway, here's the story as a sketch:
The year is 2024. After years of gravity assists from the inner planets Solar Probe+, er, Parker Solar Probe, slips into a planned series extremely close passes only 9 solar radii from the sun itself. The plan is for it to become the first human object to directly interact with the magnetic fields and plasma of the outer corona.
This would be the story of the operators of the the Advanced Technology, er, Daniel K. Inouye Solar Telescope (DKIST) in the day of and years after their unexpected discovery of persistent seemingly life-like patterns of kilometer scale plasma and magnetic fields seemingly triggered below and overlapping in time with the Solar Probe+ perihelion.
The life-like patterns of bright spots are found in the cool molecular layer of the chromosphere below the transition region. The temperature in this layer is so low that many diatomic molecules exist at equilibrium. This is where the gradient of thermal pressure to magnetic pressure is greatest and charged particles undergo "anomalous acceleration" previously unexplained by any detailed mechanism.
[The beta of a plasma, symbolized by β, is the ratio of the plasma pressure (p = number of particles*Boltzmann's constant*temperature) to the magnetic pressure (p_mag = magnetic field²/2*magnetic permeability).]
The story would be about the process of science and discovery seen through the eyes of the DKIST and other observatory technicians [not: about the personal and political fallout experienced by the scientists and technicians of DKIST as the various postdocs in the labs compete compete to try to figure out if the patterns really are life and if so what can be learned from them]. As part of this it is also about the science involved in imaging and reconstructing ~50km long bright spots just above the surface of the brightest object in the solar system. After lots of exposition about zeeman splitting, the hanle effect, poynting vectors, crossing number and other topological considerations the shape and nature of the aliens as actual life would be clearer.
As more resources are allocated and data is collected it is found that the plasmoid lifeforms are composed of dynamic arrangements of many plasmoids stuck together in patterns that "eat" opposite sign helicity magnetic flux tubes emerging from active regions. [This process would conclude with shedding single soliton waves via magnetosonic soliton conversion into shock waves that themselves break down into trains of soliton waves that propagate out into the solar wind? Soliton formation requires a balance between convection and dispersion.] The origin of nanoflares, unexplained km scale coherent radio emissions, non-thermal broadening of spectral lines in the transition region, the gamma ray excess and 40 GeV dip, and why the corona is hotter then the surface are finally explained.
Along with this human accomplishment and understanding of the outer sun references should be occasionally made to the uncertainty about the the processes occuring above the tachocline but below the photosphere. Even more mysterious is the dynamo itself in the core known only through inferences made from "G" vibrational modes of the star discovered through doppler measurements of the photosphere surface.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Yesterday I found out there is a nuclide, Beryllium 7, that has a nuclear decay where electron capture from the 2s (L shell) occurs. That's the shell used for chemical bonding in Be so the nuclear decay rate can be varied by changing the chemical environment. The decay rate can be increased by putting Be7 in a buckyball or decreased by ionizing it so that the 2s electrons are lost. That's fucking wild.
While I'm on the topic of weird nuclei tricks Thorium has an isotope with a metastable excitation state that emits a gamma ray that is such low energy it's in the UV light range, 149.7nm. ref: https://www.nature.com/articles/s41586-019-1533-4
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Update 2022-09-19: I was right. Google only ever returns < 400 search results. It will not return more. Google search *is* broken and it is broken intentionally. The differences between being logged-in and logged-out are merely the number of results per page. Even while logged out no more than 400 results can ever be returned. RIP Google Search, 1998-2019.
I've also registered googlesearchonlyreturns400results.lol and put up a little placeholder explanation of the problem. Hopefully more (and a comment system) to come.
...
Maybe I should change the name of this blog to "superkuh complains". Annoyance seems to be the only thing that can motivate me enough to post. This time around I'm annoyed at google search results being broken when I'm logged in to my google account. Searches for generic words like "vector" "surfboard" or "cat" will say they're showing x of 82,000,000 results. But if I go down to click to page 2 of results, then 3, then 4, the results run out. There are only 4 pages of results for the word "vector" and it starts reporting "~x of 381 results" instead of millions. The screenshot is a youtube link demonstrating the problem.
I didn't notice this myself. A friend on IRC was having the issue and asked if anyone else was. I thought he was just confused or bullshitting or something. But it happened to me too. I spent the next day asking around and 20 people responded. 7 of them had the problems of limited search results and 13 said google was behaving normally.
The only useful information I've been able to figure out is that it's account based. But if I am logged out and it's working and then I turn off javascript and get shunted to the mobile site the problem happens again. It doesn't matter what OS, which computer, browser, or IPv4 IP I use. So,
Bad Good
Logged in with JS x
Logged in no JS x
Not logged with JS x
Not logged no JS x
I sure hope it's just some bug and it gets fixed. I did submit a few "feedback" reports just in case someone cares. For now I'm keeping an extra browser open and logged in to google just for google services (like youtube) but it's tedious and I wish I didn't have to.
It's super weird.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
There are lots of really cool all-in-one underwater ice fishing cameras for sale commercially. Unfortunately most of them cost about $150 minimum (without most features), and more like $300-$400 for a modern brand name system. I decided to assemble my own from parts. My system ended up consisting of a vehicle rear-view back-up camera, 50ft RCA+power extension coxial cable, 12v portable digital video recorder, 7 inch LCD monitor, and a 12v 7amp hour sealed lead acid battery. Everything is done with NTSC video over RCA coaxial cable. My system ended up being comparable to an older generation low-end Aqua Vu like the Micro Stealth 4.3 ($200++) with the difference that my system can record and display video from 2 underwater cameras at once. I tested them head to head out on the ice and they are very similar in functionality and quality. The Aqua Vu's screen was easier to see in direct sunlight and it's much lighter and easier to carry around.
The waterproofing was the interesting part, otherwise it was just all plug-and-play w/RCA cables and a bit of soldering 2.1x5.5mm DC power barrel jacks. My first step was removing all screw holes from the camera by filling with baking soda + super glue (no waiting around to cure like epoxy). Before spraying silicone conformal coating over the camera I cut a tiny circle out of masking tape to cover the lens. I then sprayed everything a handful of times over three days. For the RCA connections in the extension cord I also did one spray of silicone conformal coating but most of the water proofing comes from melting paraffin wax and casting it as blocks around the standard RCA plugs. To do this I cut up some cardboard tubes and used them as molds around the plugs/cable. This was very janky looking but it worked for many hours down 15ft underwater. It might not work well above water for any long (tens of minutes) period because the RCA coax DC injector bit get hot enough to soften the wax. But easy removal is an upside compared to hot glue or epoxy. I attached everything to some scrap cardboard by poking holes and threading zip ties. I wraped it with some plastic and packaging tape.
I ended spending about $125. If someone tried to replicate it they might have to spend more because they didn't already have the spray silicone coating, a 12v charger, or bins full of DC barrel jacks, or an old power cord from something broken to repurpose for the battery cable. For this amount I probably could've bought a smaller chinese device already "assembled" but such devices don't have the capability to record video. And unlike my setup they cannot use two cameras at once for 360 degree vision. The only downsides of using such cheap ($5 shipped) cameras was the they have the vehicle back-up lines overlayed on the video. It's aesthetically displeasing but functionally it makes very little difference. Video quality was about the same as the $300 commercial system but when I use the 50ft extension cord I do get slight interference lines. I aluminum taped over the very bright white LEDs on the back-up camera since I couldn't disable them.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Tor is pretty great. It provides a free pseudoanonymous proxy to the clear web, and more importantly, it provides a secure name to address service in the form of .onion domains. For the last 15 years tor's version 2 services have been heavily used. But, they're getting a bit long in the tooth and the prefix of the hash of the private key that allows you to control a .onion domain is starting to become feasible for a powerful/rich actor to brute force. And there are security issues re: DoS types that v2 relaying allows.
So naturally the tor project introduced a new tor version, an incompatible one, called version 3. This one won't have issues with brute forcing for a long time since it has a much longer prefix of the hash used and a stronger hash function. Tor v3 was announced in 2017 and generally usable by 2018 or so with depreciation in 2021 announced in 2019.
Depreciation... that usually means, it's suggested not to use it. But that's not what the tor project meant. What they meant is that in Oct 2021 they were going to completely remove all code and support for version 2 .onion resolution from all official tor software. The clients, the relays, everything. Version 2 was to be completely killed off. For Tor, who value security above all else, there was no other option. And so, 15 years or .onion community interlinking, bookmarks, search indices, and communities just disappeared. Sure, some created a new v3 .onion domain and encouraged their users to switch. But the vast majority of .onions did not create new v3.onions to replace them. In fact, they mostly still exist and are still accessible because the relays out there still support v2. And they will until the tor project releases a new version with a consensus flag to block old versions that support v2.
So, version 2 relays are still used. The majority of sites are v2 (despite someone spamming v3 onions right after their creation to make 6 times the number of v2 onions and make it seem like v3 was getting use, v2 traffic is still more). So now people are updating their tor client software, trying to go to a tor onion website, and instead getting a error #0xf6, a generic error saying it's not a valid onion domain.
These users come to #tor on OFTC and ask why they cannot access the tor onion website. And... they won't get an answer beyond "<ggus> S17: probably you're trying to visit a v2 onion site (16 chars). the v2 support was fully removed in Tor Browser 11.". ggus has further declared to me personally that any talk about tor v2 beyond linking to the depreciation blog post will result in a ban. That's right. The tor project IRC chat is censoring discussion directly relevant to tor. Tor censoring. Laughable if the consequences weren't so dire.
They claim that no one uses v2 and that's a lie. They actively try to hide the reasons why users cannot access real tor sites. They're attacking their own userbase. And all in the name of security. Tor v2 doesn't neeed to die. It isn't even dead now, it's still very active. There need not be a single answer to, "Is tor v2 still okay to use?". That's a personal question and top-down forcing and then censorship is definitely the wrong way to address the issue.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I finally got my 3D printer working properly which meant it was finally time to learn some "real" software to do the 3D design instead of fiddling with SketchUp trying to get surface based modeling to create properly manifolded and printable items. I need to do boolean operations to 3D meshes on a linux desktop so I figured I'd try Blender.
Learning blender was slow going. It took me about a week before I could feel confident in being able to make the shapes I wanted to. So finally I got down to doing boolean operations on those shapes... and Blender can't do it. I couldn't believe it but even doing boolean differences with simple unedited meshes of a sphere and a cube will fail in almost all non-trivial cases. Differences will add, differences will create non-manifold creations, and sometimes differences won't even work at all and just create a hash of jagged edges and overlapping surfaces tied to important wall surfaces. And that's with simple geometic primative meshes. Trying to do a boolean subtract of a complex shape like a fishing lure jig from a simple cube will definitely always fail.
I spent a couple days on this trying boolean ops with simple geometries following youtube tutorials before I gave up and asked for help on #blender on irc.libera.chat. It turns out Blender is just shit at boolean operations and the problem wasn't me. So... I just wasted a week learning a program that can't do what I want. And when I threw my hands in the air and decided to just bend over and try Autodesk Fusion 360 instead I couldn't even get Firefox 88 to be able to download the installer because Autodesk uses such bleeding edge javascript/webcomponents un-HTML even a 6 month old browser can't run it.
I guess for now I'll go back to faking things with SketchUp. I'm just shocked that software with such a good reputation is so fundementally broken.
---------------
Disregard that, I was just using a 1 year old version.
It turns out that the LTS of Blender 2.8 that ships with Debian 11 *is* terrible and can't do boolean operations. But the Blender 2.9 binaries *can* and they do it perfectly for simple geometric primatives. It still can't do complex meshes but that's probably more on my mesh errors than anything with Blender.
---------------
Much learning later...
There are a lot of very finicky unpredictable tricks to gettingboolean operations to work cleanly. But the subtractions and additiosn are are mostly possible even if it takes 5 tries with lots of hacky work arounds each time. So I made and printed a type of "snap" and gliding jig that immitates dead minnows ramming into the bottom. These are super expensive right now, $12-15 if available at all. It pains me to lose them in snags. Losing 2 cheap 3/8th jig heads and some terminal tackle is much less of a problem.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
If I were suddenly and absurdly given control of pandemic medical policy at any scale I would implement two things which I believe would put *ending* the pandemic back on the table.
The first would be a "warp speed" like program to fund both existing and new intranasal sars-cov-2 vaccines that actually prevent transmission of the virus and mucosal infection. The only feasible way to end the pandemic is to stop the spread of the disease. Intramuscular vaccination alone to prevent hospitlization and hospital overload isn't enough. It is just the first step. An intranasal booster after intramuscular vaccination could stop the spread.
There are only 7 intranasal sars-cov-2 vaccinations undergoing early phase 1/2 trials right now and of them only 2 are using a sane design: one live attenuated sars-cov-2, one protein fragment of the receptor binding domain. I hope one of the two manages to clear phase 3 and be manufactured. Otherwise the only option may be ordering peptides and assembling the community designed RaDVaC sars-cov-2 intranasal vaccine at a price point of $5k for a couple dozen doses.
"the ideal vaccination strategy may use an intramuscular vaccine to elicit a long-lived systemic IgG response and a broad repertoire of central memory B and T cells, followed by an intranasal booster that recruits memory B and T cells to the nasal passages and further guides their differentiation toward mucosal protection, including IgA secretion and tissue-resident memory cells in the respiratory tract." - https://science.sciencemag.org/content/373/6553/397
The second and much less important would be both short and long term funding of N95 mask factory production and mandating N95 or better masks in all public indoor spaces. Procedure masks and unfit cloth masks do not provide protection from the wearer or to the wearer against aerosol spread respiratory viruses. They protect against spittle. That's all. Current masks laws basically only require face coverings indoors and this does nothing with giant centimeter^2 gaps through which air and aerosols flow. Their N rating is N30 to N40. Most aerosols just go around the mask. Critical to this would be a public messaging campaign nuanced enough to acknowledge that yes, prior "masks" and "mask" laws actually don't work just like the idiot anti-maskers said. But it is because most masks aren't actually masks against aerosols, not because aerosol masks don't work.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
CHIME has been my favorite radio telescope since before they even started looking for fast radio bursts. I really like the idea of using line focus from parabolic cylinders. It's obviously the most economical way to get a huge collection area/aperture. I've heard that reflections down the long axis are a problem for some CHIME uses but apparently for detecting fast radio bursts it's not. They just published The First CHIME/FRB Fast Radio Burst Catalog on arxiv and a summary article on Nature.com was on the hackernews frontpage. It looks like they really will end up detecting a FRB per day.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I've been trying to smooth out my understanding of antenna gain for years. To me it seems like aperture determines how much energy you receive regardless of multiplicative weightings provided by the directivity*efficiency gain. You can only be directive and efficient with current distributions you actually intersect with. But the more I try to tease directivity and aperture apart the more I learn they're completely coupled. You can't have changed aperture without changed directivity. But can you have changed directivity without changed aperture?
The sky pattern of a radiator is determined by the fourier transform (video) of the current distribution (video). The longer the current distribution (relative to wavelength) the tighter the pattern on the sky (higher directivity). So every time you increase the size of your antenna aperture, say by making a longer horn, a bigger dish, or adding another element to a collinear array, by increasing the current path length the summed pattern on the sky becomes smaller in angle. It seems like you can't change aperture without changing directivity.
But can you change directivity without changing aperture? I thought about adding discrete elements like inductors or caps serially into the antenna element to force excitation of different modes (say 1/2 or 3/4 instead of 1/4 for a monopole). That would drastically change the pattern... but would any feasible arrangement be feasible that didn't change the physical length of the element and so it's effective aperture? Or, even if the physical aperture would remain the same, wouldn't the forced current distribution change the *effective* aperture? Even if a mode forcing and pattern changing experiment could be feasibly built there would be severely reduced efficiency gain, entangling another variable in the mix.
And then there's the scenario where you just have many antennas, each omnidirectional and sampled by discrete receivers but later aligned algorithmically and added in the digital domain. The antenna response pattern would still be omnidirectional in that case so the directivity would not change but the aperture would change significantly (doubling in area).
Antenna gain is confusing. It seems that bigger antennas always mean smaller patterns and smaller patterns always mean bigger antennas. But I'm still not sure it *always* applies like some physical law.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
The wild grape (river grape) plants I grow for privacy and to graft table grapes onto were getting a bit overgrown and too close to the outdoor lights this spring. I decided to make a nice salad with the tender baby grape leaves and sour vine tendrils from the vines I cut down. It turned out absolutely delicious with some bacon, cucumber, cheese, crutons, and balsamic dressing.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I went fishing recently and came upon this patch of Bluegill (panfish) nest beds all packed in together along a strech of shore about 20 times the width of this photo (each bed is about 1ft across). We noticed it initially because a largemouth bass we were targeting kept returning to the area despite being spooked.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I thought I knew: A static website is a site where the webserver serves literal .html files written in HTML where the page does not need any execution of a programming language to display perfectly. I know that CSS is turing complete these days but it is mostly of trivial consequence so far. But apparently modern web dev vernacular has shifted from the "static" focusing on user experience and instead is qualifed by the dev side experience. If the contents of the HTML files are ever changed by execution of a programming language, like say, a shell script that parses a logfile, then it is no longer a static site even if the webserver only serves static .html and media files.
By that definition this wouldn't be a static website. I'm obviously biased but I don't think the modern web dev definition is very useful except in clearing up confusion with those that do.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
<superkuh> 11:47:08, Wed Sep 16, 2022 : /blog/2021-05-27-1.html/, As you found out, nope. But comments are not automatically added to the blog pages that are commented on. They are only automatically added here in the general comment page. So in a sense in-line comments displayed on the blog posts themselves are pre-moderated.
The last week has been rough. I've been on Freenode since 2001, 20 years, and I've had a registered nick since 2004. I consider it my home. Perhaps even more than I consider my current appartment my home. The people, the culture, the *help*, and the community were amazing. It was a refuge from the constant turmoil of life elsewhere in physicality and, eventually, over the rest of the internet. So it was really upsetting when I first heard that Freenode was splitting on the 16th. I spent almost *all* of my free time from then to now talking to Andrew Lee and various staff 1-to-1 getting their sides, reading the press releases each put out, and watching what happened on Freenode and Libera. It was, and is, painful. I kept hoping for reconsilliation but at this point I don't think it's possible anymore.
As far as I can tell it started when the holding company Freenode LLC was set up. IRC nerds aren't the best at legal bullshit so help from rasengan was brought in and he ended up on the board. Later christel wanted out for undetermined reasons and sold the freenode llc holding company to rasengan. At that time there was a lot of anxiety on freenode (I was there) over the new corporate ownership; rasengan/Andrew Lee has a lot of other for-profit businesses. But we, and staff, were assured that he was just doing this because he loved IRC (which I still believe) and that he'd stay out of server operations.
At this point rasengan owned the holding company that owned the domain name. Everything else, the servers, the DNS control accounts, etc were owned and operated by staff. That includes setting up the relationships for third parties to donate servers to freenode.
With christel's departure the staff got together and decided to vote tomaw as the new freenode leader to handle server operations. Things were okay for a while.
Then there was a hiccup with rasengan putting a little ad/link for one of his for-profit companies on the freenode website. That acted as the catalyst for tension and tomaw asked for full control of the domain name.
Things became more tense when, after some time of freenode staff contributing to the dev of an updated IRCd they made a post about it on the blog about switching to it. This was a problem for rasengan since his overarching goal with IRC.com and ownership of IRC networks (like snoonet running on IRC.com resources) is to set up a truly distributed IRC where any server can peer to any other and easily switch networks. He'd put in a significant amount of money into developing this IRC.com IRCd, I've heard. And this provided his motivation to opposing the staff's switch to their modified IRCd for future operations.
This was now rasengan interering directly in the operations of the freenode network. And the heated debates this caused eventually lead to litigation by rasengan against tomaw. At this point it was obvious that christel/rasengan's statements about the sale were just words and that now legal means were going to be used to take control of the operation of the servers.
They drafted their various resignation letters, some got leaked early on the 16th. At this point I got involved as a regular user on #freenode and talked to rasengan there and on Hackernews forums. I also talked to the staff. Even then I personally hoped for reconciliation. But apparently it wasn't possible. Legally, Freenode LLC (if not actual freenode, the people and servers) was owned by rasengan. So the staff decided to resign in mass.
Based on rasengan's behavior, and the type of new staff he appointed, I think that libera represents the ideals and people that make up Freenode far more than Freenode itself does anymore. I'm trying to move but it's going to take a long time to let everyone know what's going on. Most, reasonably, don't care about network drama.
Anyway, I look forward to seeing you all on irc.libera.chat going forwards.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Most language that rapidly add new features gets those features used and that causes the need for containerization on any machine with a release older than $shorttimeperiod. The problem is not old code forwards but code from today back to whatever your distro had at release. With fast moving languages like Rust, Python, and moreso these days even C++ with it's extension you'll eventually find your system repos don't have the required version to turn arbitrary new source code into a running program. It could be a pyenv or a container (flatpack, snap, appimage, docker, etc) but something has to bring in *and contain* the unsatisified deps and provide them.
But I've never had to do that for a Bash or any shell script. They just run even on decades old installs. I assumed this was because bash wasn't getting new features and was just bug fixes and maintainence at this point. But I was wrong. Bash does get new features all the time. Features that older bash versions cannot run.
<phogg> rangergord: bash changes *all the time*. It just doesn't break backwards compatibility very much.
<superkuh> It does?
<phogg> superkuh: was that intended for me?
<superkuh> Yeah, I'm genuinely surprised. I thought it was just bug fixes and such these days.
<phogg> superkuh: New features with every release, too.
<hexnewbie> superkuh: People simply don't follow the Twitter feed with new features to use them, so you're far less often surprised. Come to think of it, the amount of cmd1 `cmd2` I see suggests even less up-to-date coders :P
<superkuh> Well, that destroys my argument.
<phogg> superkuh: the POSIX shell command language changes, too, although much more slowly--and absolutely without breaking things.
<hexnewbie> In Python everyone's *dying* to have that feature *yesterday* (that includes me)
<phogg> superkuh: see https://lists.gnu.org/archive/html/bug-bash/2019-01/msg00063.html and https://lists.gnu.org/archive/html/info-gnu/2020-12/msg00003.html for the two latest bash releases.
So why don't we have bash script compatibility problems? I don't know. None of my guesses are based on very much information. I will again just assume that most people, most devs, that work in bash don't care about the latest and greatest. They care about having their script run on as many machines as possible as smoothly as possible. I've been thinking about language/lib future shock in the wrong way. It's not the rapidity of the language that causes it. It's the culture of the devs using it.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Comments:
1:14:21, Tue Aug 17, 2021 : /blog/2021-05-07-1.html/, for more than a decade, bash is the shell i relied on. not only do i have it installed, its one of the few things ive compiled from source. i never was much into more limited shells, i never was much into newer fancier ones, i just used bash like a new standard. now that ksh comes with openbsd, i find it is more predictable and less tedious. the reason? fewer features. fewer gotchas in what a string does. some of those substitutions are useful, dont get me wrong, but the stability of ksh is what makes me appreciate it. i am tired of massaging code to work in bash, it has too many rules. and thats after years of tryig to rely on it. simplicity wins here. obviously dos was even simpler, but it did next to nothing and that wasnt enough.
For the last 15 years or so I've made sure to put all my websites on both the clear web and tor. I liked tor because I believed that I owned my domain name on tor. This is unlike the clear web with DNS and registrars merely leasing you a domain name. But it turns out that even on tor you don't own your domain name.
Today I learned that the Tor project is killing off *all* tor v2 domains in October 2021, a handful of months from now. All of the tor web, the links between sites, the search engine indices, the rankings and reputations for onion domains, they will all disappear in a puff of smoke. I never really owned my tor domain. I owned my keys but The Tor Project owns the domains. And the Tor Project has decided to take my domain away from me.
Yes, I understand why tor v2 is depreciated. The hash of the keys is short enough that brute forcing a prefix to imitiate some v2 address is nearly possible. But v2 has worked alongside v3 just fine for a couple years now. The idea that they have to completely remove it is false.
And the consequences of doing so are dramatic. The very heart of the tor web will be destroyed. All the links, the search indices and rankings, the domain reputations and bookmarks will all disapear. Some of the domains may create a new website using tor v3 but it will have no link back to the v2 version. The web of tor sites will simply disappear. Decades of community building gone in an instant.
I thought tor was useful for owning my domain but I was wrong. I no longer see any reason to run tor onion services and I will not be creating a v3 service like I'd been planning to. I guess nows the time to try i2p.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Comments:
1:13:08, Sat May 1, 2021 : /blog/blog.html/, It's not just the key length, there are lots of other vulnerabilities that make v2 onions fundamentally unsound and insecure. It isn't just about you, the host it's also about protecting the identities of the people who installed Tor to browse the internet safely and anonymously. Personally, I don't think that search rankings and reputations are much of a concern since onions are almost exclusively discovered by word-of-mouth, onion-location headers, and webrings. The deprecation period has been very long, any actively updated onion site should have added a v3 link a long time ago. Lastly, of course it's not your domain you're joining a network of volunteer-run servers with a consensus - you can feel free to run your own network if you want complete control of the domain, but it's going to be awfully lonely. Anyway, I hope you change your mind and decide to keep a v3 site, but I'm interested in hearing more about i2p as well
I decided to take the opportunity to get in a little guerilla gardening on the now dry empty lake bed. The city plans to start seeding of fast growing grasses to reduce erosion later this year. But there'll be a brief 1-2 year window before any actual landscaping with native plants is done. I figure I can get a single season of growth in without too much disturbance. And if any of the trees I try seeding (oak, maple, birch, thornless honey locust, walnut) get going maybe the city will keep them.
This is what the lake used to look like.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Sometime between last night and this morning my Cree 4-Flow style LED bulb had the phosphor coating pop off one of it's LED emitters. It is now shining a bright violet light along with the warm white of the others. I don't think there's any danger from this but it isn't very nice asthetically.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Everything is being written or re-written in Rust these days. It has genuinely nice features and it's hip. Unfortunately it is the least stable compiler/language in existence. Rust's "stable" versions don't even last a year. Something written in Rust 1.50 can't be compiled and run on even Debian 11, a distro *not even released yet*, with Rust 1.48 from 2020-11-19. Rust versions don't even last 5 months.
For all it's safety and beauty as a compiler it fails spectacularly at being able to compile. This is why every single Rust tutorial you see demands you not install rustc from your system repos (no matter how new) and instead use their proprietary and shady rust-up binary that pulls down whatever it wants from their online sources. The idea of a compiler that you cannot get from your repos is absurd and that needs to be recognized.
Rust is cool, yeah, but it isn't a real language yet. It's just a plaything for coders right now. It is not a tool for making applications that can be run by other people. Eventually as a different demographic of devs begins using Rust they'll stop using the fancy newest backwards incompatible extensions and only target "stable" versions. And at that point Rust will slowly become a real language. But that day is not today.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Some claim old computers should be replaced with modern computers because modern processors have far lower idle wattages. A mid-range Intel Core2Duo 6400 from the 2008 era idles at 22w. Compare that to modern processors like my mid-range Ryzen 3600 at 21w.
A better argument for replacing older PCs is the last decade of lowering prices for 80% gold and higher efficiency power supplies that can actually delivery this efficiency at idle loads.
But any efficient modern power supply should be able to power an older computer too so this doesn't change much.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I recently built a new PC for the first time in a decade. I'm struggling with a number of surprising and distasteful changes to computing practices on both the hardware and the software sides. This is my list of modern computing annoyances and the partial mitigations so far.
1. Stock coolers sold with $200 CPU are no longer capable of cooling those processors and aftermarket cooling is required. My Ryzen 3600 went to 95C and throttled within 20 seconds with stock cooling. Conversely the stock cooler with an Intel 3570k from a decade ago not only kept everything below 80C but it did it even with a massive overclock. Buying a $45 aftermarket cooler fixed this.
2. It's easy to forget that even if you build a fancy new computer if you use an *old* BIOS video card you *CAN NOT BOOT IN EFI MODE*. And while I like BIOS-mode more than EFI mode at some point in the future I want to actually buy a modern video card. It may be when I get a modern card I'll have to resize my partitions to make an EFI boot one, somehow switch my OS boot process to EFI while still using the old videocard (impossible to confirm success because it won't display on EFI boot) and then put in the modern EFI video card. Additionally, with being forced into csm/BIOS mode for my boot that means I now have a GPT formatted and partitioned drive with a MBR master boot record that's actually what is being used for booting. I wasn't even aware that was possible before doing it.
3. All desktop environments have suffered from "convergence" with mobile design styles and slowly bitrot. Gtk3 File Open dialogs no longer have text entry forms for filename and paths by default. This prevents pasting into a just opened open dialog until you press ctrl-l. And the gsettings switch for this no longer functions. Gtk devs confirmed this is as intended and gtk3filechooserwidget will stay this way. My attempts to create a patch so far are feeble at best and only restore the filename-entry location mode for the first File->Open operation of each application load.
I've been poking at gtkfilechooserwidget.c and .ui for about 2 weeks now. Of course the first thing I tried was just changing the initialization function settings for location mode. But it turned out operation mode had to be changed too (thanks Random!). But that only fixes for the first file->open operation. In order to permanently fix it I think the best path forward is to artificially send the GtkFileChooserWidget::location-popup: signal on initialization of pretty much any function that looks like it works on location mode or operation mode. I've tried doing this using location_popup_handler (impl, NULL); but I haven't fixed it yet.
4. Just because systemd Debian 10 has cron/crontab and syslog don't expect them to actually work. syslog won't update it's time when the time is changed and so cron won't either. Additionally, crontab -e no longer updates cron immediately. Instead all changes are updated at the start of the next minute. This means if you try to test a crontab -e entry you need to set it for at least *2* minutes into the future, not just one.
I'm calling it now. Long term covid-19 disease will be found to be mostly a side effect of abnormal cell-cell fusion due to the membrane fusion mediating properties of the basic terminal of the protease cleaved spike protein in sars-cov-2 particles. There are many studies in lung, heart, and cell culture model tissues showing abnormal cell fusion happens, and happens far more with sars-cov-2 than it does with sars-cov-1 (or other lipid enveloped viruses). The inflammatory effects of these persistent merged cells would cause the weird immune response (ie, parasitic factors being expressed along with viral throwing immune response off) and long term issues in the surrounding tissues of the organ.
Of course there's a lot more going on in long term covid-19 than just this accidental side-effect cell membrane fusion. Stuff with the angeotensin signaling being completely messed up to due competitive binding by sars-cov-2 spike RBD, and the circulatory damage this causes can't be ignored. Or even the normal cytotoxic effects of all viral infection. But the cell fusion bit has it's role to play and I think it's an important one.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Pandemic dreams suck. I keep dreaming I'm in crowds of people, and then, slightly lucid, I'll think, "Why isn't everyone wearing mask? Why don't I have a mask?!" and I freak out in the dream and run off or hold my breath or something stupid and dreamy. Comon' dream self, get it together. Put on the mask before you're being chased through a shopping mall by monsters. Be prepared. Jeez. It's been a year.
Unrelated, the lake that has been in the center of my town since the 1920s has been drained recently due to flood damage in spring. It's a giant flat mud-plane made of polygonal mud tiles with a deep cut river flowing through it now.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I see a lot of people comparing the mag-loops to full size dipoles as if they were equal options. Electrical small mag-loops are a compromise antenna. Just by normal physical considerations it is obvious that a mag-loop is a much less sensitive antenna than a full sized half wave resonant dipole. Before even talking about the trade-offs in size vs impedance bandwidth vs efficiency and chu-wheeler-etc, there's effective aperture to consider. At HF frequencies (1-30MHz) the near field of some tiny LC oscillator (like a 1m mag-loop) is pretty damn large. But it is not as large as the size of a 1/2 wave dipole. So from the start a full size antenna is just intercepting *more* energy. Efficiency or radiating (and so reception because they're reciprocal) scales proportional to the physical path in space the currents travel over relative to wavelength. If the effective aperture doesn't subtend a decent fraction of a wavelength you just don't get, or emit, effectively. Electrically small mag-loops will always start ~20 dB down from the performance of a loop, or a dipole, that is a good fraction of a wavelength in effective aperture. And even just to get that relatively okay performance the impedance bandwidth is proportionally tiny.
You can, of course, get back a lot with LNA for reception. That's the beauty of radio, the absolutely boggling scale of power magnitudes over which it can work and still pull out the information. It's why you can stick your cell phone in a microwave but still get calls. A 30dB attentuation is a normal situation for a radio link and information can still be recovered. But the power... you lose most of the power in the first 6 dB loss. And that's why wireless power transfer will never work and microwave oven doors and electrically small mag-loops do.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Is it better to have max power emitted spectral density everywhere and be flat, or have the same integrated energy but space out channels in the frequency span available? I think this is only a real question in the context of human laws on emission power rather than some information theory idea. It seems obvious that you want to fill in and use the entire frequency span to the absolute limit so it'd be even.
You can do that kind of thing with IQ based sampling and signal processing because it is designed for shifting information in frequency. But with something like 1gb ethernet (PAM5) that doesn't use a carrier and just changes the voltage level of a baseband pulse, one of 5 states -2, -1, 0, 1, 2, there's no way it's evenly filling the available frequency span, is it? In the frequency domain the very fast pulses are are the superposition of a bunch of very high frequency components. But does the PAM5 pulse shape result in an even and full filling of the available spectrum? I doubt it. It's probably a lot of power at the higher freqs and not much in the lower. It's a waste and it creates frequency requirements for the transmission line that are not proportional to actual summed frequency span used.
Over the same frequency span the, admittedly much more complex, RF-based solution gets much closer to the information theoretic capacity of the transmission line all things held the same. We could have 50 gigabit ethernet on the same transmission line tolerances that baseband modulated PAM5 ethernet requires for 1 gb. The transceivers would cost a lot more though. Ethernet is conceptually simple in ignoring the frequency domain. But that is just pushing more and more complexity into the magnetics of the transceivers and the quality of the transmission line.
Maybe it's time for RF ethernet again? It worked for Docsis. 70 ohm twisted pair isn't bad for RF over quite a range.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
A few years back I put some lame jokes in my robots.txt and said a hello to any human reading it. Yesterday someone(?) took a string from that greeting and set it as their bot's user-agent while mirroring a large part of the site.
...
User-agent: Zombies
Disallow: /brains
User-agent: Killer AI
Disallow: /~superkuh/
User-agent: The person who is reacting to the lame jokes that is reading this robots.txt right now. Yes, you.
Allow: /hello/awarenessofthemeta/
...
Well... hello person. I really enjoyed the out of band mechanism you've used to talk back. Either it's that or some very weird bot behavior pulling substrings from robots.txt as a random user-agent.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I've been growing "Titan" sunflower seeds for about 6 years now. They result in large white/grey seeds. Last year some of my Titan plant heads were cross pollinated and came up with black seeds. When I planted those black seeds this spring these purple seeds resulted. The purple was pretty intense. It even stained my fingers.
I was harvesting the seed heads early because the squirrels (and birds) had taken more than half of them. I could see the local squirrel was very upset by my audacity to take any of the seeds for myself. It stared at me the entire time alarm calling and flicking it's tail.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Stargate SG-1 is the best scifi TV show that has existed so far. Some of it's spin-offs were pretty good. Others, like Stargate Universe, were just okay. But Stargate Universe did have a very interesting plot device. In it they were in a spaceship traveling across galaxies setting down a chain of stargates (wormholes). The ship itself seemed to be trying to read a message in the cosmic microwave background radiation. Neat, right? But the tone of the show was weird and not stargate'y so it was canceled after the first season with no explaination of any of the plots.
I always thought the best resolution of the Stargate Universe plot was that the Destiny spaceship was traveling across the universe in order to get enough baseline distance and so interferometric resolution to see the data encoded in the fine structure of cosmic microwave background. When the ship calculates it is far enough away that the detail encoding the message can be resolved they'll fire up the chain of gates connecting Destiny back to the first end of the telescope, manufactured by the Ancients, creating an interferometer the size of an entire galaxy cluster.
It gives a reason for the ships behavior that's both scientifically plausible and fits in perfectly with the canon plot.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
The Flash plugin is being forcefull killed off by Adobe now, years after Apple first banned the plugin from safari and started the trend. Adobe's newly distributed plugin will come with a time-limit baked in and eventually stop working. This is another reason I'm glad I don't upgrade my software to the same versions across all physical machines.
I have a 2006 era computer with 2010 era software. A 2010 era computer with 2013 era software. A 2013 era computer with 2016 era software. All but the last is well outside of official software support. But I'll always be able to easily play Flash media if I want to because I can just load it up on my 2010 era machine. And on that machine the Flash plugin creates /proc/ temp files on disk so you can directly interact with the swf files. The old machine's HTTPS cypher set and TLS protocol might not be acceptable to a modern fancy website but I can always use a $modern era machine to grab the files w/curl-or-wget if I'm not loading from disk.
This also applies to things like GNU Radio. I can still run any GR 3.6, 3.7, or 3.8 flowgraph I find online. No more loading up a flowgraph to see a bunch of missing blocks. Instead of having to try to port things each generation I just leave them in-place, working, and then wait a couple years longer than most people to adopt the newest version of things on an entirely new machine. Like the xkcd comic says, it pays to live in the past.
Obviously this means security holes that aren't patched. I can't backport everything or provide static compiled deps for all of userspace. But for the most security problematic programs, like browsers, the kernel, x.org, it's usually possible. But these days security is more about attacks through your browser's VM or router's interface than your actual OS's programs.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
It won't be too long before browsers (and search engines) stop accepting HTTP at all and getting permission from a centralized authority for your TLS cert will be required to host a visitable website. Even the most popular federated protocol, smtp, is being centralized and soon the big email walled gardens will require TLS for all transport if only to prevent surveillance. But the very means used to avoid government (and other) surveillance will give those entities complete control of our most popular communication systems.
TLS means that every single server is only allowed to exist at the end of a very long leash back to a centralized provider of certs. Even if that provider is currently benevolent, dot org shows what can and will happen with time and money. No one is going to be accepting self signed and with no other option, suddenly things are centrally controlled. Non-encrypted mail and web and everything have their place.
Sorry to harp on this subject again but I keep seeing people saying that it's time to *enforce* TLS for everything these days. Even if there's no malicious behavior enforcing TLS brings in a single point of failure you can't control. Higher-up cert authorities mess up regularly.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Trying to go forward through time as fast as possible.
It's been a while. For those of you coming from the far future (hopefully is hasn't gotten worse) the gap in posts was because I was trying to sleep my way through the beginning of the pandemic. But life goes on and there are only so many hard scifi books to read. I've just been trying to go forward without making memories so it'll seem to pass by quickly. But since I'm still only shopping once per month (since Feb) that makes doing technical projects on a whim harder but not impossible.
1. Squirrels are the enemy.
Lately I'm working on a few things. First and foremost is what everyone else is doing: gardening. Gardening sure is fun. Except for the squirrels. I can plant a seedling, cover it with chicken wire for a month, remove the chicken wire, and the next day the now established plant gets dug up. The squirrels have been trained by the neighbor feeding them for 20 years. They think all bare dirt is just some other squirrel's hiding spot. So, after losing about 40% of my garden I caved and bought a trap. So far I've caught 3 of the little tree rats. I've been relocated them 10mi east out of town. It seems to be helping. You can't get rid of squirrels but I can at least get rid of these trained ninja plant assassin squirrels and trade in for some new ones that don't suck.
2. Excess crystalization driving pressure is the enemy.
My second project have been making little PID temp controlled water baths and stirrer to grow large single crystal KDP (Potassium dihydrogen phosphate) and TGS (Triglycine Sulfate crystals). My first efforts with very slow evaporation being the only driving force worked well for a while, but then crystals started forming on the bottom of the containers. So I started pouring the solution into new jars every day. Then eventually the saturation would get too high and dendritic forms would appear and cloudy main crystals. So I started over but this time I add a few ml of clean water every night that I change the jar. So far this is working well to make large clear single crystals. Once I have a few a cm or so wide perpendicular to their optical axis it'll be time to try using them as seeds to grow large boules.
The above crystal was the seed I started with. The crystal now is almost too large to fit in the quart mason jar. I'm mostly making the KDP for practice without having to waste my previous synthesized TGS but in the end it might be fun to try two-photon harmonic upconversion with them. The purpose for the TGS crystals is pyroeletric acceleration. Although making a simple bolometer might be fun too.
3. Flow is the enemy.
At one point I started going out and making random dams across local rivers. That was a nice way to get away from everyone else but still exercise.
4. Routing cables and coaxial cable cost is the enemy.
Just this evening I cleaned up and reconnected all my HF (1-30 MHz) radio transceiver but removed the manual tuner and the 1500w amp from the chain. I threw together the most janky and simple of all possible dipoles using an F-connector with no balun, and the two wires connected to it were each dumpster dive finds made of multiple sections soldered together. In the end each half of the dipole was about 20ft (6.3m). Not a lot to work with. But it's about all that I could fit up into my maple tree using the slingshot/fishing line method without getting close to powerlines or making it obvious. The other half I ran along my house and off to the disconnected garage. Total parts costs was about $5 (no including the $10 zebco fishing reel and $10 slingshot).
My Kenwood TS-450S with it's basic auto-tuner seemed to be able to match it over a pretty good range from 3.8 MHz up to 28 MHz. I'm sure it wasn't actually radiating that well but I did manage to make contact on 80m with a guy down in florida with voice. A good afternoon project.
But that was just checking everything still worked. My next project will be a 3m diameter 4" wide aluminum flashing magnetic loop antenna attached to the inside of the back of the garage. I plan to just let the flashing overlap 9 inches or so with transparency sheet between to the ~200 pF needed for ~3.975 MHZ I want. That should be just under the near vertical incidence scattering edge and cover a nice 100-600 mile donut around me to try mesh stuff. But that's a story for another day.
5. We have always been at war with headphone cables.
As per usual, my headphones started going flaky on one side. Too much shock or torque or bending stress. After 3 previous repairs, each lasting a few years but shortening the cord, I decided to bite the bullet and replace the cord entirely. I cut a long male to male extension in half for the purpose and this final cord is about 5m long. I can now scoot around in my chair with impunity. No cord pulling. It sounds the same.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
[attention conservation notice: this is just me venting anxieties about the pandemic]
Seriously. Fuck.
There are many types of believing. You can "believe" in religion but for most people it doesn't really effect their actual behavior. And even if it does at some level it's not like military generals out there are planning for what to do if god intervenes. It's a belief but it isn't held in the same context as other beliefs.
Back in 2005 I learned about the vulnerability of the health care system to viral pandemics. I believed in them and it scared the shit out of me. I was embarrassed later for doing typical "prepper" things like buying a 3 month food supply and rotating it, buying boxes of n95 masks, etc. I believed, but I didn't really anticipate anything concretely out of h5n1 influenza despite my obsession that well crossed the border into mental pathology.
At first I talked to everyone around me about it. There was serious danger. Not saying anything would be like not saying, "There's a bear behind you." But this was obviously not received well and for good reason. I slowly stopped with this negative feedback. I just did things quietly. Then years passed and nothing happened, and nothing happend, and something happened (2009 swine flu) but it was all okay. I eventually, thankfully, became convinced by others and the lack of realization that it wasn't a realistic scenario. That was good. I couldn't really function believing otherwise. I stopped rotating food and gradually forgot about my anxieties.
Now this. The nightmare that I had every night and day for 5 years but painstakingly moved past is real, or at least part of it is. The rest is excruciatingly uncertain. It's surreal and terrifying. I hadn't had an anxiety attack in almost a decade till yesterday at the grocers seeing my fears in everyone else for the first time.
And I don't even get to fucking say "I told you so." because I stopped believing. I never really believed.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
You hear about on the news every month now. $x store is opening a location that allows shoppers to buy without human interaction, without a checkout. Restaurants are slowly but steadily being replaced by food trucks which won't take your order unless you pay with a credit card first, no cash allowed. Browsers and search engines both are starting to refuse to display websites that don't exist on the whim of some leased SSL cert saying you're part of the established corporate order. Soon no businesses will accept interacting directly with human persons. All transactions, all interaction, will require a third party corporation (one whom is almost certainly extracting rent) to do the transaction for you.
It's so fast, so easy, so convenient. All the complexity and awkwardness is hidden from the human persons and their life is easier. But a chain around your neck is still a chain no matter how long you make it. Human person motives and corporate person motives rarely align and in the future when there's a disagreement it's clear who's going to make the decisions about what is allowed and what is not: the corporate people everyone loves and depends on.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I had a bit of a freak-out back around 2005 when I learned about influenza pandemics and H5N1. I did all the things from buying basic supplies (and rotating food for years) to working with a friend online (over AIM w/trillian) to come up with an over-the-counter route to synthesize oseltamivir (tamiflu).
For example the starting material, furan, can be sourced from corn cobs (furfural from corncobs, 2-furancarboxylic acid from furfural, furan from 2-furancarboxylic acid). Or, far more feasibly, just extracted from it's use as a solvent from a commercial product. The current pandemic reminds me of that fun but wasted effort. It's presented below so someone might get a kick out of it.
OTC Oseltamiver Synthesis
By Chris The Great, 2006
This document has not yet been tested to ensure that it works as presented.
Step One: Synthesis of A
Methyl acrylate (2.78mol) is added to furan (3.95mol) and cooled to -10*C. AlCl3 in DCM (1.15mol in 1-5M conc.) is added slowly with stirring, keeping the temperature below -10*C. The mixture is then cooled with a cold water bath and stirred for 2 hours. The mixture is added to 1000ml of saturated sodium bicarbonate solution, and the precipitate is filtered out. The aqeous layer is extracted twice with 250ml DCM, and the organic layers are combined and dried over anhydrous sodium sulfate. The solvent is distilled away and the product purified by silica gel column chromatography to give the desired product in 38.6% yield (1.07mol).
Step Two: Synthesis of B
A (1.07mol) is added to NaOH (1.65mol, 3 to 15M concentration) in water with stirring, maintaining a temperature of 5*C. The mixture is allowed to warm up over a period of 30 minutes with stirring, and stirred at room temperature for 2 hours. HCl (310ml of 31% sol.) is added to adjust the pH to below 1, and then the mixture is extracted 4 times with 200ml of DCM. The combined organic layers are dried with Na2SO4, and solvent evaporated and the product recrystallized from ethyl acetate to give the desired product in 87.5% yield (0.936mol).
Step Three: Synthesis of C
B (0.936mol) is dissolved into 850ml water, and NaHCO3 (0.936mol) is added slowly, with stirring to control the foaming. After foaming ceases, bromine (0.936mol) is added dropwise with stirring, and then the mixture is stirred at room temperature for 2 hours. The mixture is extracted with 400ml ethyl acetate, washed with 100ml thiosulfate solution (to remove unreacted bromine) and dried with Na2SO4. The solvent is distilled away and the product purfied by recrystallizing from ethyl acetate, giving the desired product in 89.6% yeild (0.84mol)
Step Four: Synthesis of D
Potassium hydroxide (2.5mol) is dissolved into dimethylacetamide (1000ml) and methanol (150ml), and C (0.84mol) is added slowly as the mixture is heated to a gentle reflux. It is stirred under reflux for 3 hours, then ethyl iodide (1.6mol) is added and the mixture stirred under reflux for another 3 hours. To the mixture is added HCl (300ml 31%) and the solution extracted with ethyl acetate (250ml) eight times. The organic layer is washed with saturated brine and dried with Na2SO4. The solvent is distilled away and the product purified by recrystallization to give the desired product in 95.9% yield (0.804mol).
Step Five: Synthesis of E
A solution of sodium methoxide (0.9mol) in tetrahydrofuran (500ml) is cooled to -30*C, and D (0.804mol) in tetrahydrofuran (500ml) is added dropwise with stirring. After the addition, the mixture is stirred at 30*C for 1hr. To the mixture is added acetic anhydride (1.05mol) and the mixture is stirred at room temperature for 3hr. To the reaction mixture is added saturated ammonium chloride (1000ml), and the mixture is extracted with ethyl acetate (800ml). The organic layer is dried (Na2SO4) and the solvent distilled away. The product is recrystallized (ethyl acetate) to give the desired product in 80.0% yeild (0.644mol).
Step Six: Synthesis of F
E (0.644mol) is dissolved into 3-pentanol (600ml) at reflux, and AlCl3 (0.7mol) is slowly added with stirring. The mixture is stirred at reflux for 1 hour, and then allowed to cool to room temperature. A saturated solution of NaHCO3 is added (1000ml), and the mixture is extracted with 750ml DCM, washed with saturated brine (750ml) and dried with Na2SO4. The solvent is distilled away and the product recrystallized (DCM) to give the desired product in 81.2% yield (0.522mol)
Step Seven: Synthesis of G
F (0.522mol) is dissolved in DCM (750ml) and triethylamine (0.78mol) is added. The mixture is stirred at room temperature for 5 min. and then cooled to 0*C. To the mixture is added tosyl chloride (0.78mol) and the mixture is stirred at room temperature for 1hr. The reaction mixture is washed with saturated sodium bicarbonate solution (1500ml), saturated brine (750ml) and then dried with sodium sulfate. The solvent is distilled off, and the crude product recrystallized from DCM to give G in 97.3% yeild (0.508mol).
Step Eight: Synthesis H
G (0.508mol) is dissolved in ethanol (1000ml) at reflux, and potassium carbonate (0.25mol) is added with stirring. The mixture is stirred at gentle reflux for 1.5 hours, and then cooled to room temperature. Saturated ammonium chloride solution (1000ml) is added. The mixture is extracted with DCM (750ml), washed with saturated brine (1000ml) and dried (Na2SO4). The solvent is distilled away and the crude product recrystallized from DCM to give H in 98.5% yeild (0.5mol).
Step Nine: Synthesis of I
H (0.5mol), sodium azide (0.6mol) and ammonium chloride (0.6mol) are dissolved into water (70ml) and ethanol (250ml), and refluxed for 8 hours. Aqeous NaHCO3 (105ml of 8% solution) is added and the ethanol distilled in vacuum. The aqeous residue is extracted with ethyl acetate (250ml), the extract washed with water (125ml). The wash is back extracted with 125ml of ethyl acetate and the combined organic extracts washed with brine (125ml), dried over Na2SO4, filtered and concentrated in vacuum to give I as a dark brown oil in 102% yield (0.512mol)
Step Ten: Synthesis of J
Step One:
J (0.512mol) and ammonium chloride (1.2mol) are dissolved into ethanol (1500ml), and zinc (0.7mol) is added and the mixture refluxed for 30 minutes. The solvent is distilled off to give Ib, which is used directly in the next step.
Step Two:
Tosysl Chloride (1.13mol) is added portionwise at room temperature to a stirred mixture of Ib (from the step one), K2CO3 (2.5mol) in acetonitrile (1000ml) and stirred for 6hr. Toluene (2500ml) is added, the solid is filtered off and the solvent evaporated to give J in approx 80-90% yeild. It is used directly in the next step without purification.
Step Eleven: Synthesis of K
J (0.494mol), sodium azide (1.2mol) and ammonium chloride (1.2mol) in dimethylacetamide (400ml) is heated to 80-85*C for 5 hours. NaHCO3 (50mmol) in water (250ml) is added, and the mixture extracted with hexanes (6x250ml). The combined hexane extracts are concentrated to 1200ml, and 250ml DCM is added, followed by 1100ml NaHCO3 8% solution and acetic anhydride (0.6mol). The mixture is stirred at room temperature for an hour, and then the aqeous layer is removed. The organic phases are concentrated in vacuum to 430g total weight), dissolved in ethyl acetate (50ml). The mixture is cooled and K crystallizes out and is collected by filtering. The crystals are washed with cold 15% ethyl acetate in hexane (250ml) and dried in a vacuum at room temperature, to give K in 55% yield (0.272mol). [may be slighly higher, ie 60%]
Step Twelve: Synthesis of L (oseltamivir freebase)
K (0.272mol) is dissolved into ethanol (600ml) along with ammonium chloride (0.64mol). Zinc (0.36mol) is added and the mixture refluxed for 30 minutes. The precipitate is filtered out, giving L in 98% yeild (0.266mol). [90-95% more likely]
Step Thirteen: Synthesis of Oseltamivir Phosphate
L (0.266mol) is dissolved in acetone (1000ml) and treated with phosphoric acid (85%, 0.266mol) in absolute ethanol (300ml). The mixture is cooled, and after 12 hours the precipitate is filtered out to give oseltamivir phosphate in 75% yield (0.2mol, 82g). A second crop of presumably lower purity crystals can be obtained by concentrated the solution and collecting a second crop of product.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Today in my RSS feeds an APS paper summary came up called, "Heat Flows in a Circle Without Gradients. It was about this ring of spaced ring oscillators that supported both mechanical excitation modes and phonon modes but where phonon excitations flowed around forever. It's interesting but more interesting was the offhand comment in support of infinite currents saying,
Undriven flows do occur in nature, as evidenced by persistent electric currents in permanent magnets and superconductors.
At first I thought they might be talking analogy, like spins as currents or electron "orbits", or something, but no, the wikipedia article, https://en.wikipedia.org/wiki/Persistent_current#In_resistive_conductors talks about real nanoamp currents physically existing. And then that leads to any even weirder rabbit hole.
I feel like that I can normally ignore quantum physics when doing radio and electromagnetics work. I don't do a lot of polarization stuff and quantum effects normally average out in imprecise many-sample systems. But apparently at specific mesoscopic length scales the quantum stuff I don't understand actually starts coupling to electromagnetic excitation modes. But the gist is that there's a neutral AC oscillation normally and applying an external magnetic bias to these magnetic material rings creates an internal asymmetry causing an perpetual tiny electrical current to flow.
This type of persistent current is a mesoscopic low temperature effect: the magnitude of the current becomes appreciable when the size of the metallic system is reduced to the scale of the electron quantum phase coherence length and the thermal length. Persistent currents decrease with increasing temperature and will vanish exponentially above a temperature known as the Thouless temperature. This temperature scales as the inverse of the circuit diameter squared.
And it does so in regions where there should be both zero electric and magnetic field the https://en.wikipedia.org/wiki/Aharonov-Bohm_effect. It's apparently strong philosophical support for the mathematical formalisms of the electric and magnetic potentials (as opposed to fields) as *real* physical things and beyond that delocalized physical things.
The Aharonov-Bohm effect, sometimes called the Ehrenberg-Siday-Aharonov-Bohm effect, is a quantum mechanical phenomenon in which an electrically charged particle is affected by an electromagnetic potential, despite being confined to a region in which both the magnetic field B and electric field E are zero. The underlying mechanism is the coupling of the electromagnetic potential with the complex phase of a charged particle's wave function, and the Aharonov-Bohm effect is accordingly illustrated by interference experiments.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
There are two mutually exclusive views of the web. As a set of protocols set to allow individual humans to share information about things they love and the web as a set of protocols to make a living.
Profit motivated web presences want views, they want attention, they need nine 9s uptime, need to be able to do monetary transactions absolutely securely, and they want to be an application not a document. They live and die on the eternal wave of walled garden's recommendation engines because that's the network effect and that's where money flows. It doesn't matter if this means extremely high barriers to entry because money solves everything.
Individuals' websites are freeform presentations about the things that person is interested in. They are the backyard gardens of the mind and the most important thing is lowering the friction from thought to posting. There's no need to get tons of traffic instantly (or ever), they're mostly time insensitive.
Year by year browsers' evolution into another OS are creating new barriers to entry for those wishing to host personal website. Just one tiny example of this is browsers (and search engines, and etc) requiring HTTPS and not just SSL certs but only certs with lifetimes less than 1 year. All this piles on, destroys access to old web content, and generally creates cyber gentrification. With the WC3 now marginalized and corporate run web standards groups (ie whatwg) setting the protocols there may soon come a time where it's infeasible to run a website without relying on a third party entity to do some part of it for you.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
█▓▒░ Comments ░▒▓█
20:54:11, Tue Feb 25, 2020 : /blog/blog.html/, Re: web security fetishism. Without HTTPS, an adversary can man-in-the-middle your connection and do all kinds of nasty things, from surveillance, to denying access, to altering the content, to running arbitrary javascript exploits against users' browsers. Given that certbot is free and now auto-renews your certificate for you on most platforms, I can't say that it is an especially high barrier to rule out this class of attacks, which may not be a personal threat to you, but can have severe consequences for the vulnerable. And although it does require trust in a 3rd party, which is not ideal, everybody is better off with it than without it.
re: random commenter above, as you can see from this site of mine I do like and use HTTPS. But I think HTTP has a valuable and essential place beside it. Going only HTTPS is bad. Going HTTP and HTTPS is great. Browsers and search engines punishing, hiding, and demonizing HTTP sites in their listings or notifications does more damage than then some potential downgrade attacks.
Reliance on third parties is also a bad idea. Sure, letsencrypt is great, but it's also causing extreme centralization of the web since it's so nice. The .org situation shows that no matter how benevolent and longstanding institutions that have power will be corrupted. And no matter how "easy" it is, acme2 is not a simple protocol. There's tons of complexity hidden behind that "easy" that has to be supported over time and changing software stacks.
Memory is two different systems both operating in parallel at the same instant of perception.
There's the short term awareness as encoded in the ~40 Hz cortico-thalamo-cortical loops of active cortical neuronal populations. The binding in time of different types of cortical processing at the thalamic relays and stimuli representation are essential to, if probably not all of, conscious awareness.
There's also the long term encoding in the entorhinal cortex (3 layers transitions from the 5 of cortex to hippocampus "simplicity") and hippocampus which itself is a multiple component system encoding different properties of the new experience relative to existing memory and relations. There is "pattern separation" about encoding distinct new properties of some experience and "pattern completion" which encodes in terms of the past to extract meaning in terms of known relations. And both of these are referenced through two spatial coordinate systems (especially in CA3). The meaning is all in terms of place.
Distinguishing between things (pattern separation) and seeing how things are the same (pattern completion).
During sleep the spatial coordinate system "paths" of the day are revisited in activation backwards in time and the specific episodic and spatially referential memories of the hippocampal formation are generalized in reference to thalamo-cortical loops.
Recall of memory later depends on self-reinforcement of thalamo-cortical loops populations. Over time memories which a person holds as truths can actually shift based on their own biases and other associations which help form/hold that memory.
Consciousness is the turbulence of prediction that tries to minimize itself.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
<superkuh> I've never had solder wick that wasn't shitty.
<superkuh> Does such a thing exist?
<OdinYggd> Flux core.
<OdinYggd> aka make the entire flux dish hot, put the braid in the liquid flux, then let it cool
<OdinYggd> ONce you pull it out the entire braid will have flux throughout, and will actually wick up properly
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
This "Large Instruments For Exoplanet Direct Imaging Studies beyond TMT/EELT/GMT" talk by Prof. J. R. Kuhn (IfA, Hawaii) is very cool but it reminds me a lot of Robert Charles Wilson's print scifi story, "Blind Lake". In it the near future telescopes don't really even perceive the sky anymore. The sky is the start but in terms of computation triggering but it's almost the least of the input compared to the the models and priors and arcane unknowable quantum-woo-woo which synthesize the detail of the resulting images. Not to imply there's any quantum woo-woo here. This is really cool science.
more adaptive optics instead of expensive stiff structures
don't grind glass, actively bend 2mm thin glass and retain a smooth surface
incoherence happens, let the neural networks sort it out
In this talk Kuhn makes the call for building a large multi-mirror optical interferometer to capture enough photons to do model-based time-series reconstruction of the surface features from light reflected off exoplanets. The proposed optical telescope is an interferometer, a donut of moderate size circular apertures, that are combined to form a speckle interference pattern. Each circular mirror in the donut has adaptive optics who's arbitrary phase shift can be found with neural networks then changed arbitrarily to create nulls in the combined UV coverage directly as a function of diffraction to act as a super low noise coronagraph.
Optical interfometry is tough and phase error kills. Normally to be big things have to be made super stiff. He argues that the telescope structure doesn't have to be built any more rigid than the amount of atmospheric turbulence they already correct. From this premise he suggests a bicycle wheel like tension and compression design to minimize weight when flex can just be adapted.
But even moderate size mirrors cost a lot and so do adaptive optics. To make this cheaper he shows a small scale implementation of a mirror made out of an extremely thin bit of non-ground, perfectly smooth glass. To create the phase needed locally to cancel out the local surface error + atmospheric surface error + wobbling error he shows an electroactive polymer that can be 3D printed onto the thin glass itself and under an applied electrical field (as a dieletric in a capacitor) it can pull on the local glass surface. Without a need to grind the mirror it can be extremely smooth and relatively cheap.
All together it seems like a powerful system for making a cheap big light bucket. But what strikes me most about it is that the information needed for the coronograph nulling is being derived from a seemingly nonsensical speckle pattern with lots of unknowns. They just throw a neural network at it and tell it to create some inversion function(s?) that takes incoherent speckle pattern information and somehow comes up with the mechanical phase error.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
In cold climates in winter human drivers don't follow the official lane markings because they can't be seen. They follow the paths in the snow everyone else has packed down. These paths often diverge from the road markings. Any attempt to create an absolute positioning rather than vision based system like humans use is doomed to failure. No amount of technology injected into roads rather than cars will help because that's not how humans drive and humans are the priority users of the road transport system.
This doesn't just happen during and after snowfall. It's a permanent feature of side streets for months. It's not a transient effect. Regulation of autonomous land vehicles in cold climates will have to be different from temperate ones.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
This is me finally picking back up a 2018 project to design flexible and cheap RF frontend filter for rtl-sdr dongles. I've had the parts laying around for years but never actually tried for fear of breaking the ICs. I only have 10. 9 now.
I put down the tac'y flux, then I put tiny bits of old temp solder using a tiny conical tube on each exposed pad. Some was overlapping but I cleaned it up with tweezer tips. Then I did hot air just above the melt temp till it resettled. At first the nozzle was too close and I blew away some solder but I think enough was left. Unfortunately, as you can see, I don't think the bottom pin flowed properly. It might be time to get a cheap hotplate or something so I can reflow things evenly without burning the ICs.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
I don't want to have any "moving parts" in my static website. I also don't want to have to rely on any third party services. To support webmentions (and pingback) all you really have to do is log HTTP POST request body. To do this with nginx you proxy it to itself so it thinks it's passing to a cgi script and define a custom log format to handle POSTs for the wemention endpoint location.
# /etc/nginx/nginx.conf for debian-style
http {
# just the request body, hopefully source=...&target=...
#log_format postdata $request_body;
# extra info in csv
log_format postdata '$time_local,$remote_addr,"$http_user_agent",$request_body';
The log output looks like whatever someone submits. But assuming it's webmentions with two variables it might be something like this,
# /etc/nginx/sites-enabled/default.conf for debian-style
# use $server_name instead of $binary_remote_addr IP match so the pool is for the whole server
limit_req_zone $server_name zone=webmention:1m rate=2r/s;
...
server {
...
# use proxying to self to get the HTTP post variables.
# https://stackoverflow.com/questions/4939382/logging-post-data-from-request-body
location = /webmention {
limit_req zone=webmention;
client_max_body_size 7k;
if ($request_method = POST) {
access_log /var/log/nginx/postdata.log postdata;
proxy_pass $scheme://127.0.0.1/logsink;
break;
}
return 204 $scheme://$host/serviceup.html;
}
location /logsink {
#return 200;
# use 204 instead of 200 so no 0 byte file is sent to browsers from HTTP forms.
return 204;
}
Then you can look at the log with your eyes at a later time and respond if you want to. Manually (using curl). Any including of their response in your page will just be from going there in a browser and copy/pasting or whatever. You could script that too but it seems like a hassle and open to abuse.
To make it easier to others I put an HTTP POST html form at the bottom of posts that points to my /webmention endpoint like shown below. The way I do this in nginx with HTTP 204 return code means, well, there's no response. It just happens silently. That's fine with me even if it confuses people. Feel free to play with this one and submit whatever strings you want. Webmentions, pingback xml, a perl script, ascii art, whatever.
As far as my tests go and using other's online testing tools my implemention and endpoint seems to be detected and I get the data in my logs. I'm redundantly putting the <link ... > webmention tags in all posts, at the top of the main indexes, and in my HTTP headers.
Since nginx is the only thing exposed and all it's doing is logging to disk and there's no increased dangers of exploits or abuse. The only real danger is someone trying to fill up the disk with lots of POSTs. But the log file size can be easily managed with system tools like logrotate and by limiting connections per second and max body size. At max it should be about ~900 MB of logs per day which triggers logrotate at the start of the next day and clears them.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.
Today while on a walk with a friend in the cold winter woods a cockatiel parrot flew down and landed on my head. It eventually moved down to my shoulder and stayed there seemingly content. It was obviously someone's distressed pet. It flew off on the walk back to find a temporary place for it and I assumed it would die of the cold later that night. So... I went back an hour later and managed to whistle, gesture, and coax it down on to my shoulder where it had no problem sitting for 15 minutes while I asked people in the area if they were missing a parrot (really). None were, of course, but one helpful group in a parking lot took a photo for me and posted it with my phone number on a local-centric 'lost items' forum. Meanwhile, I gave up and the parrot had no problem coming home with me on my shoulder in my car.
About an hour later, after I'd resigned myself to having to buy parrot food and start putting down newspaper, I received a call from the owners of the parrot. They'd seen the post and after giving them my address they said they'd be over in 30 minutes. A woman and her son arrived and confirmed it was their parrot. They'd lost it the day before, so it had managed to survive a night. It was a pretty happy reunion scene and I'm glad I took the time to save the bird.
The bird was super cute but given birds' pooping habits I think I was almost as relieved as they were it was going home.
[comment on this post] Append "/@say/your message here" to the URL in the location bar and hit enter.


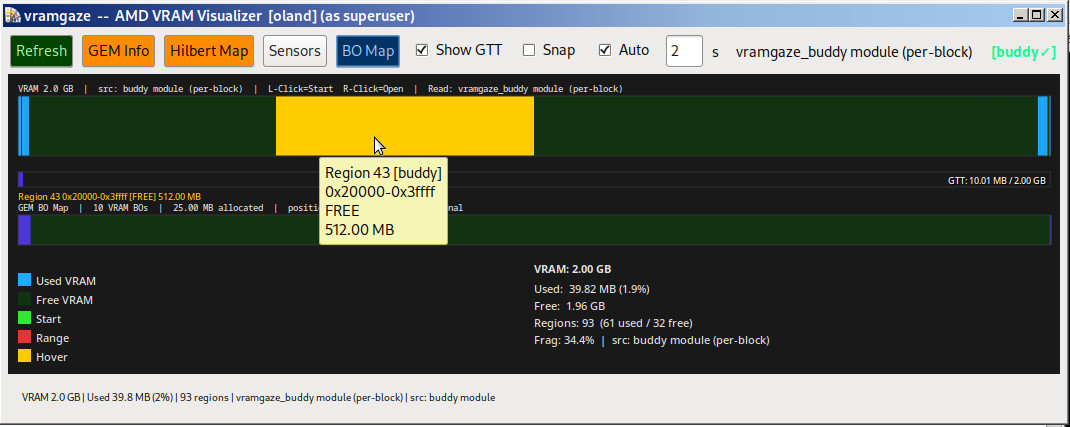
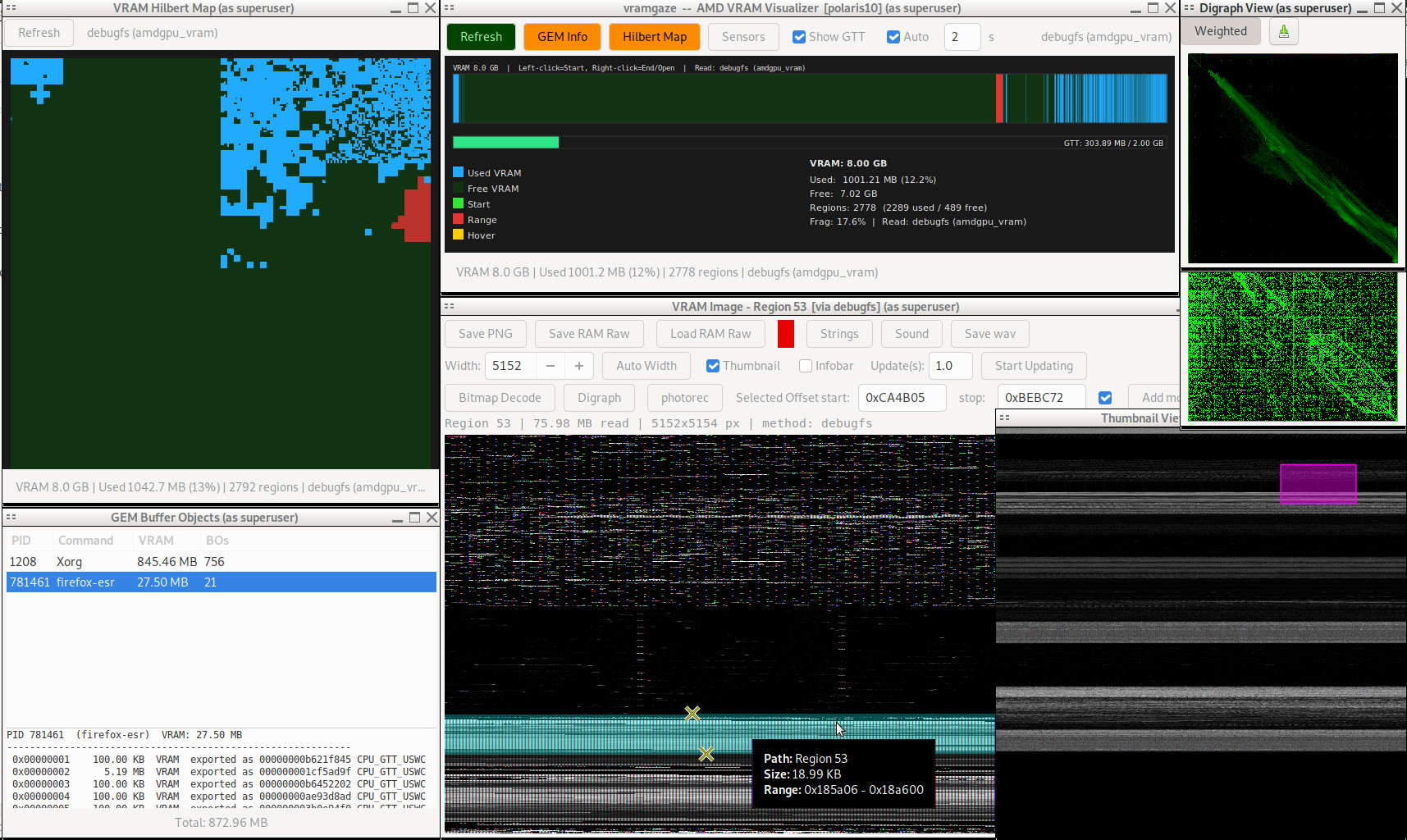
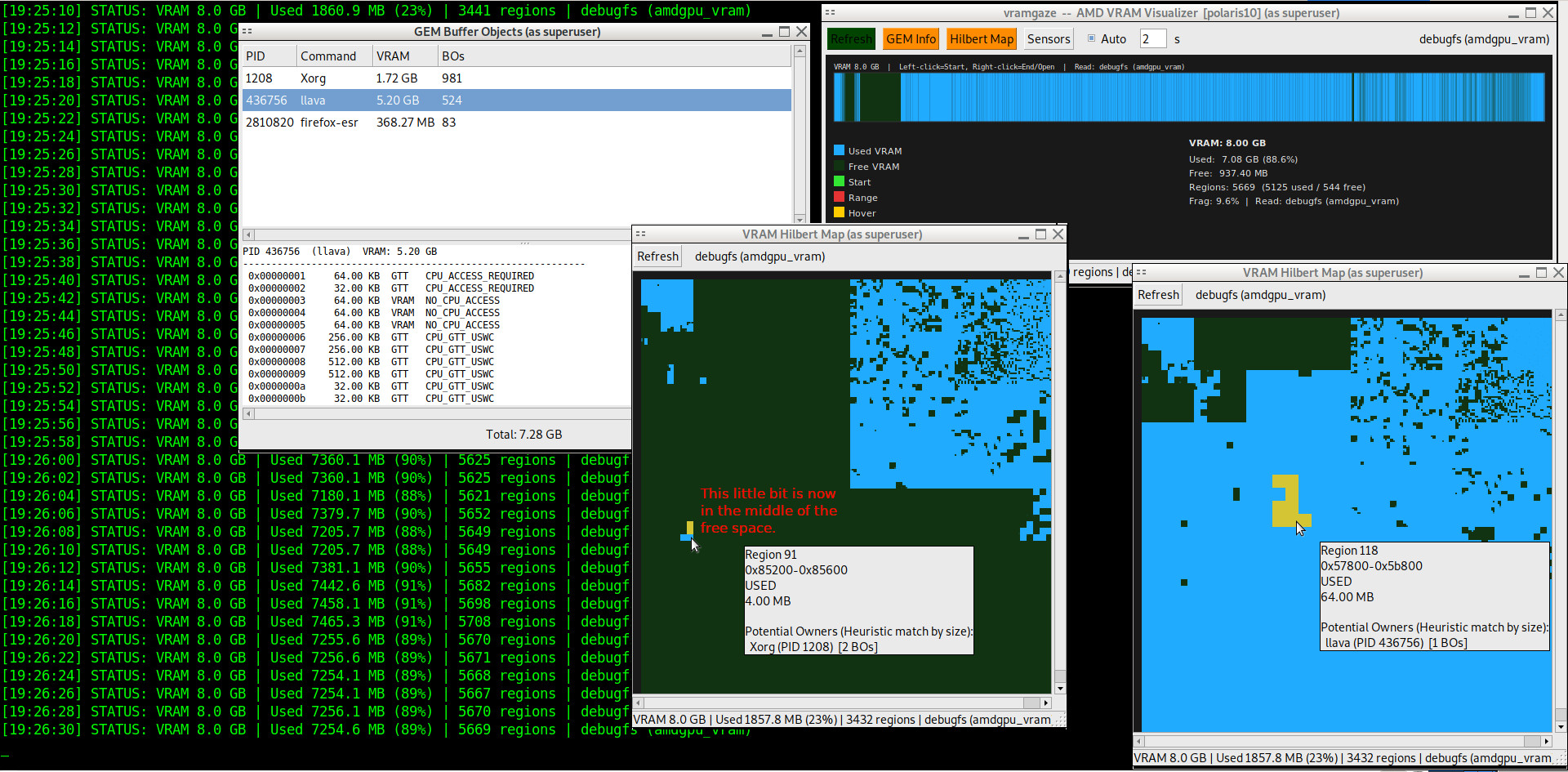
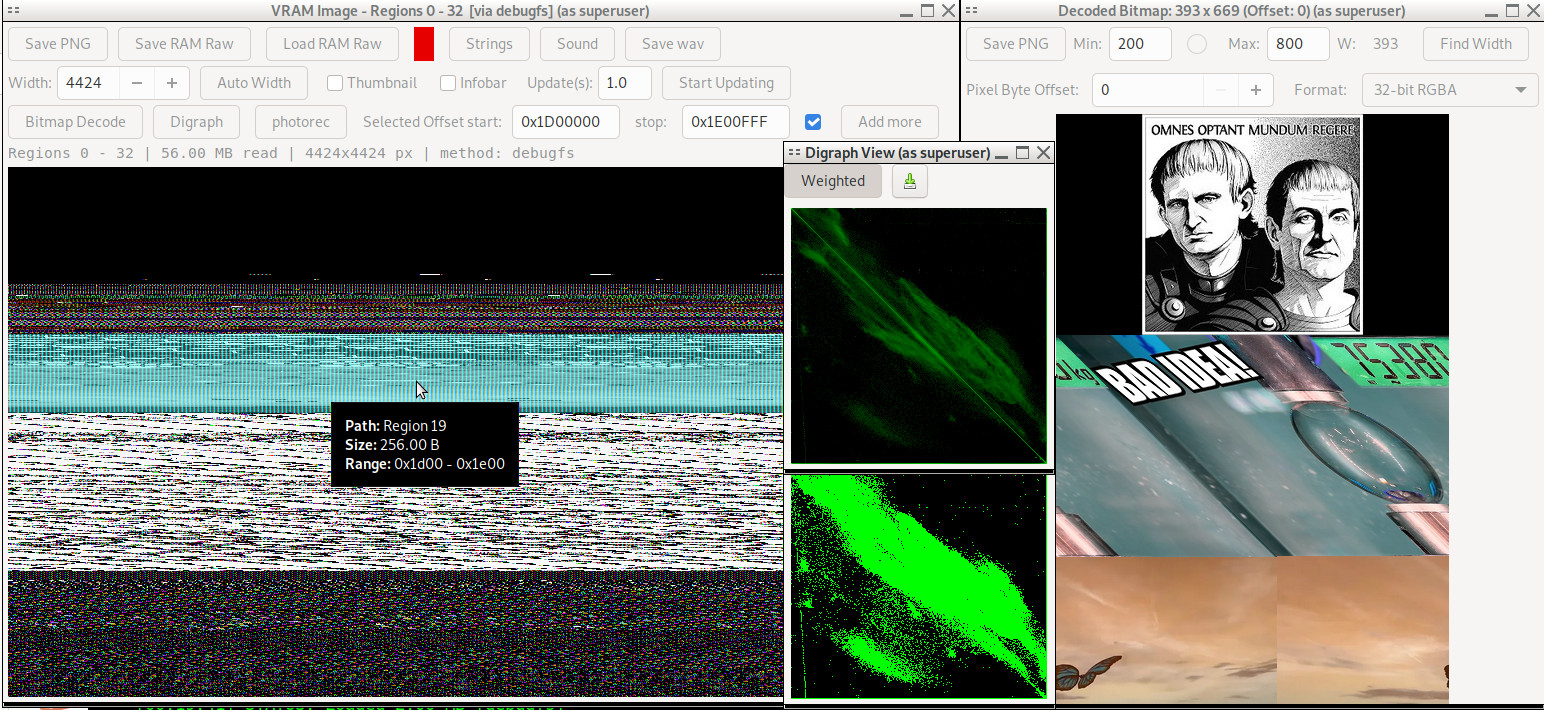


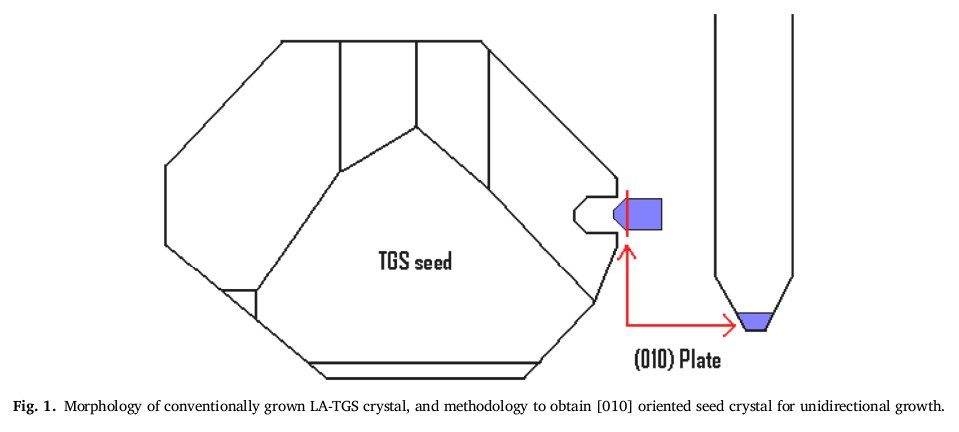



















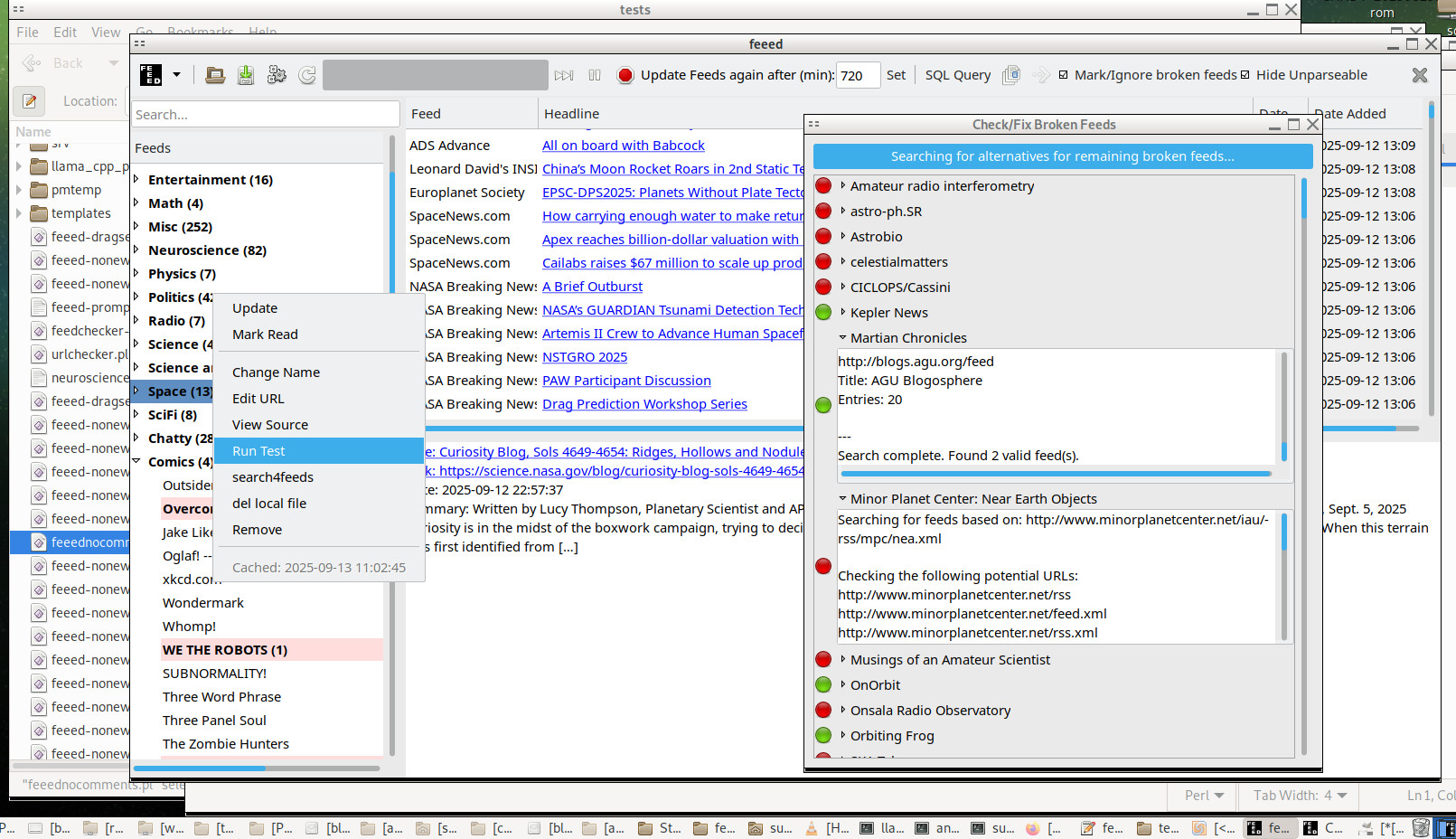
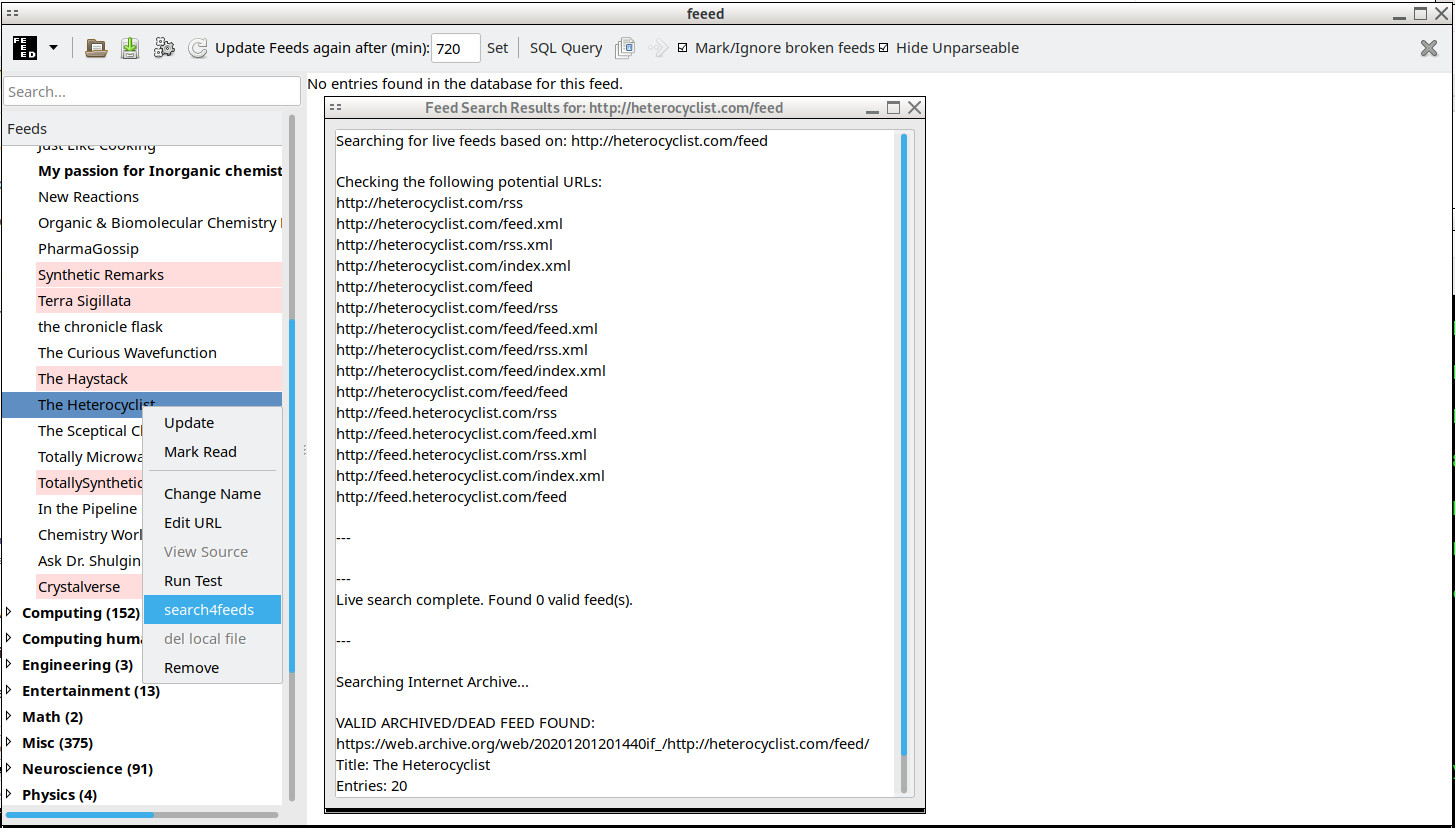
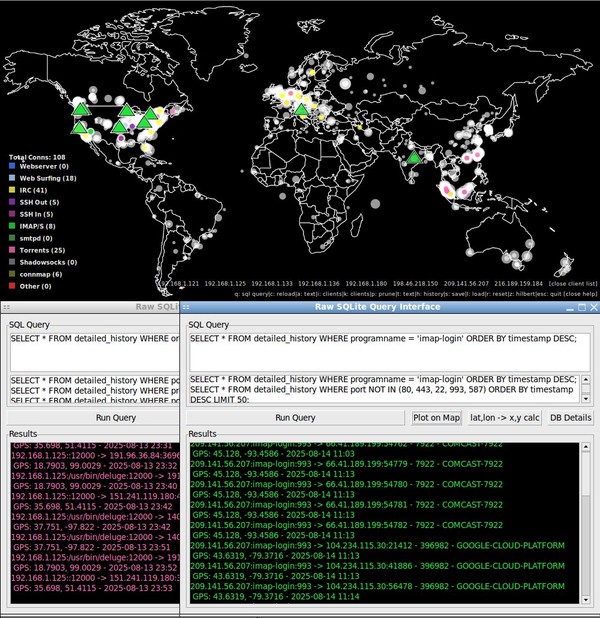
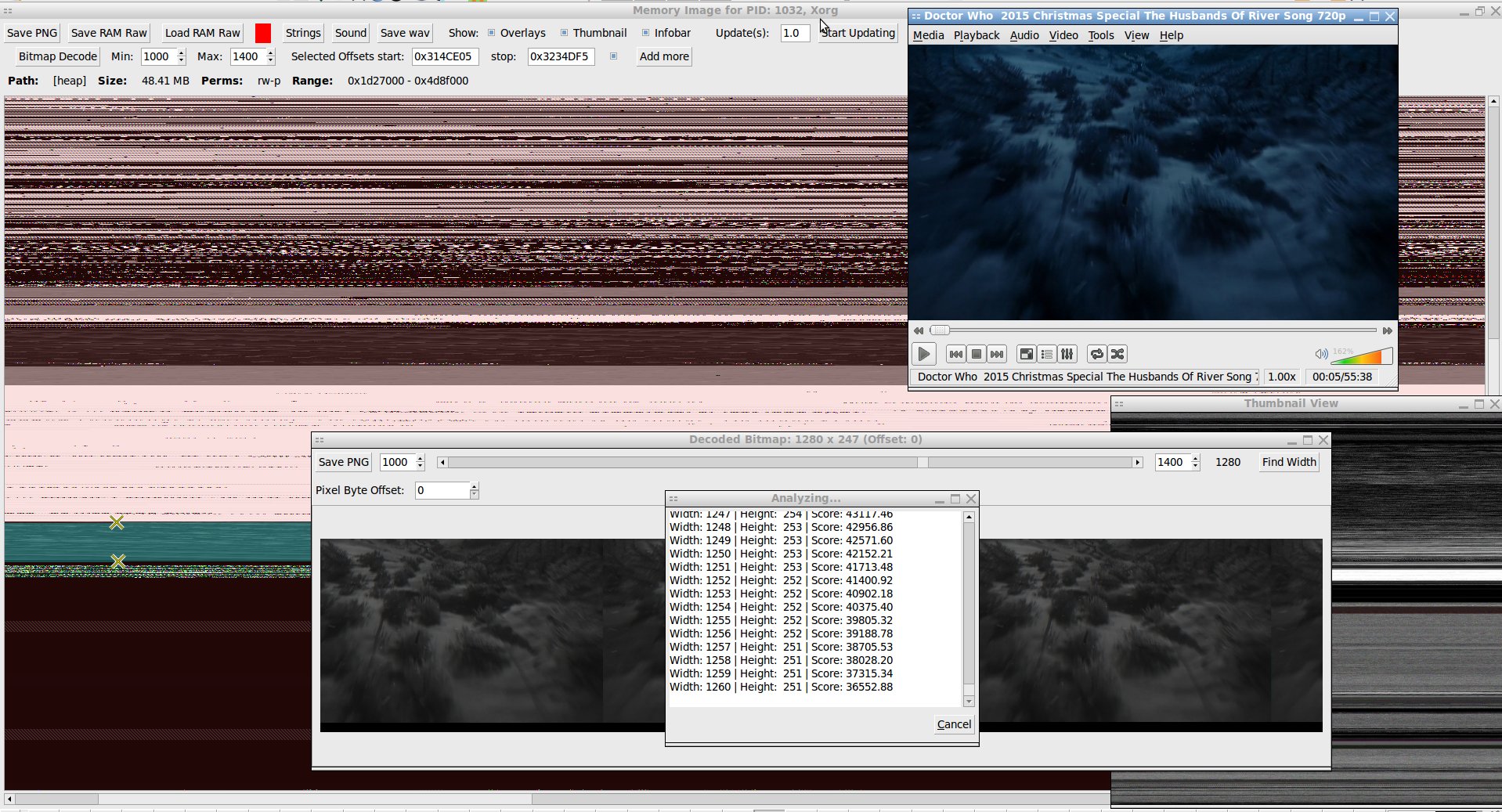
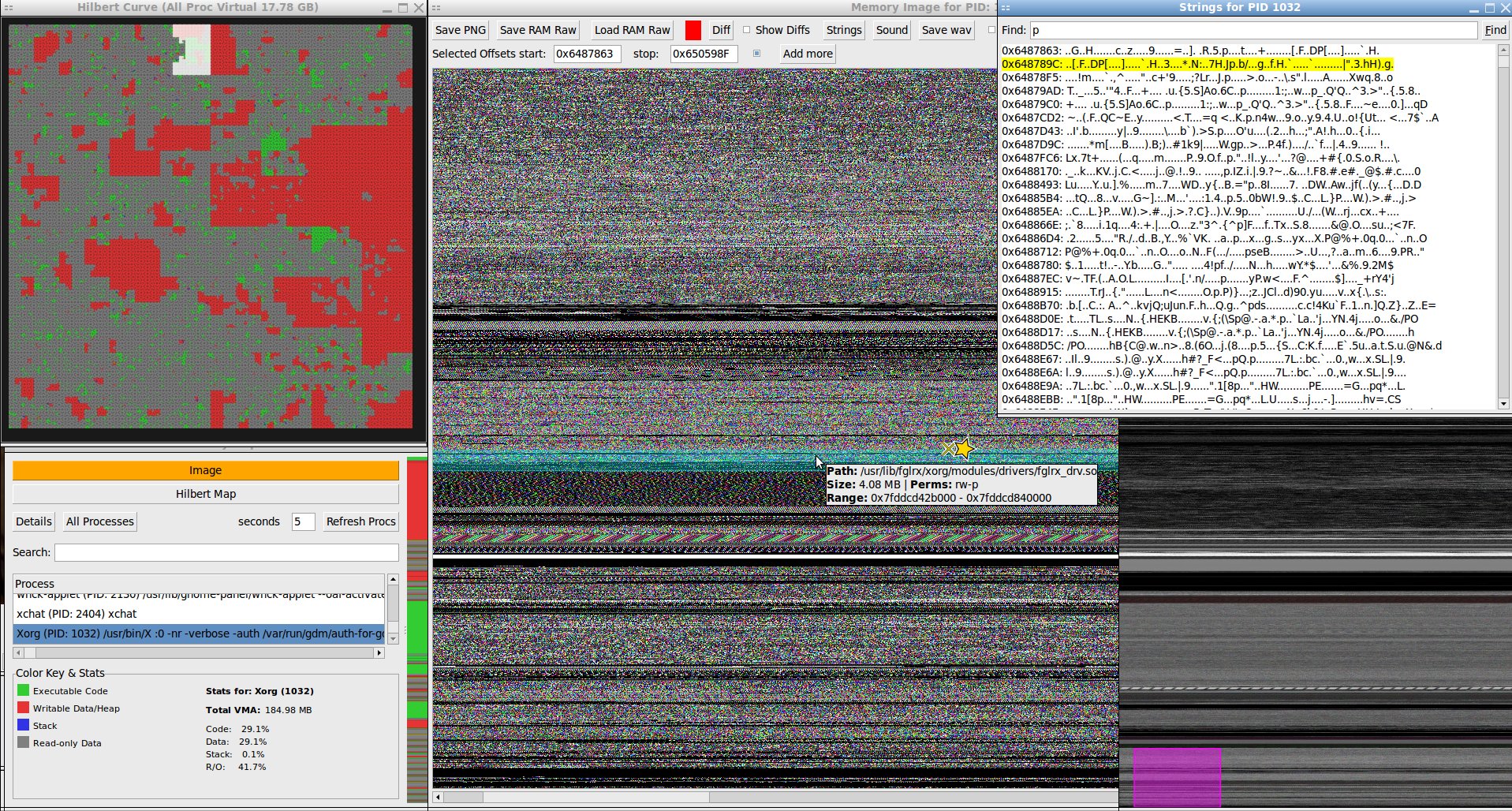

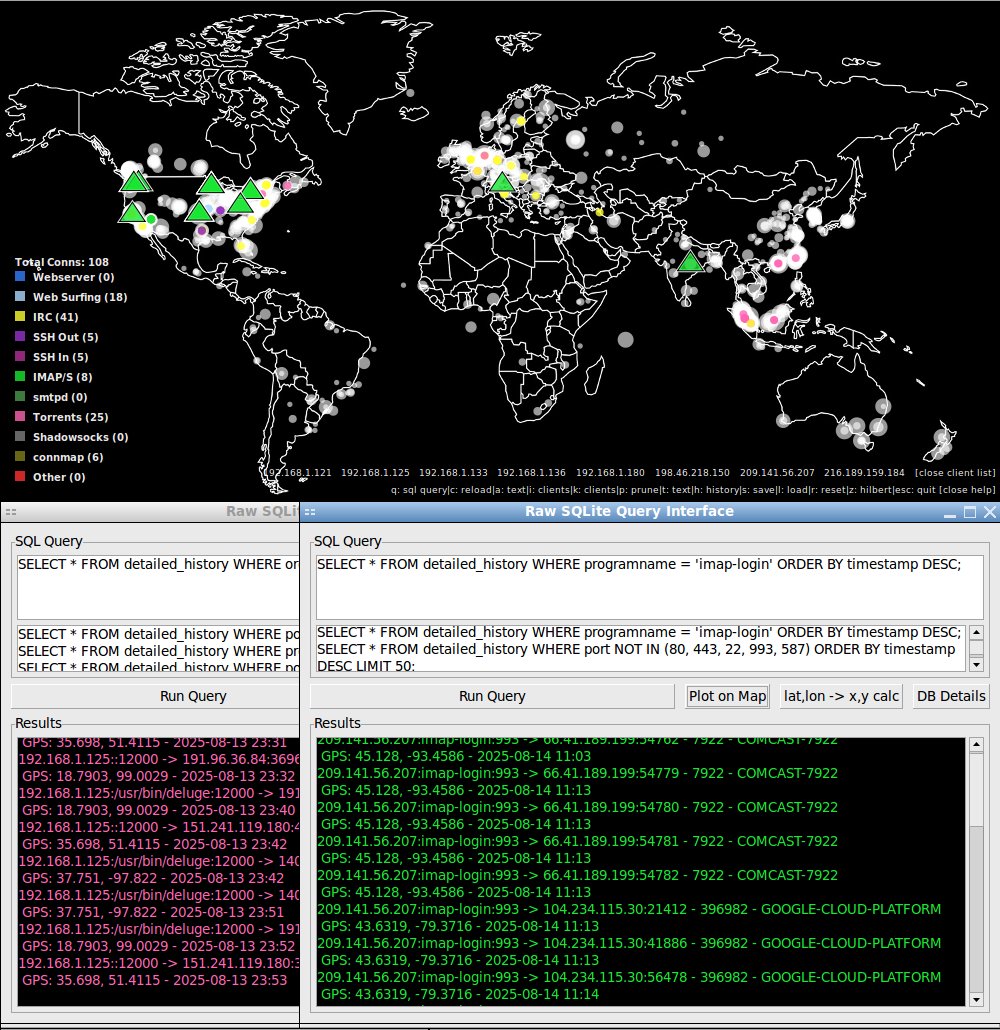
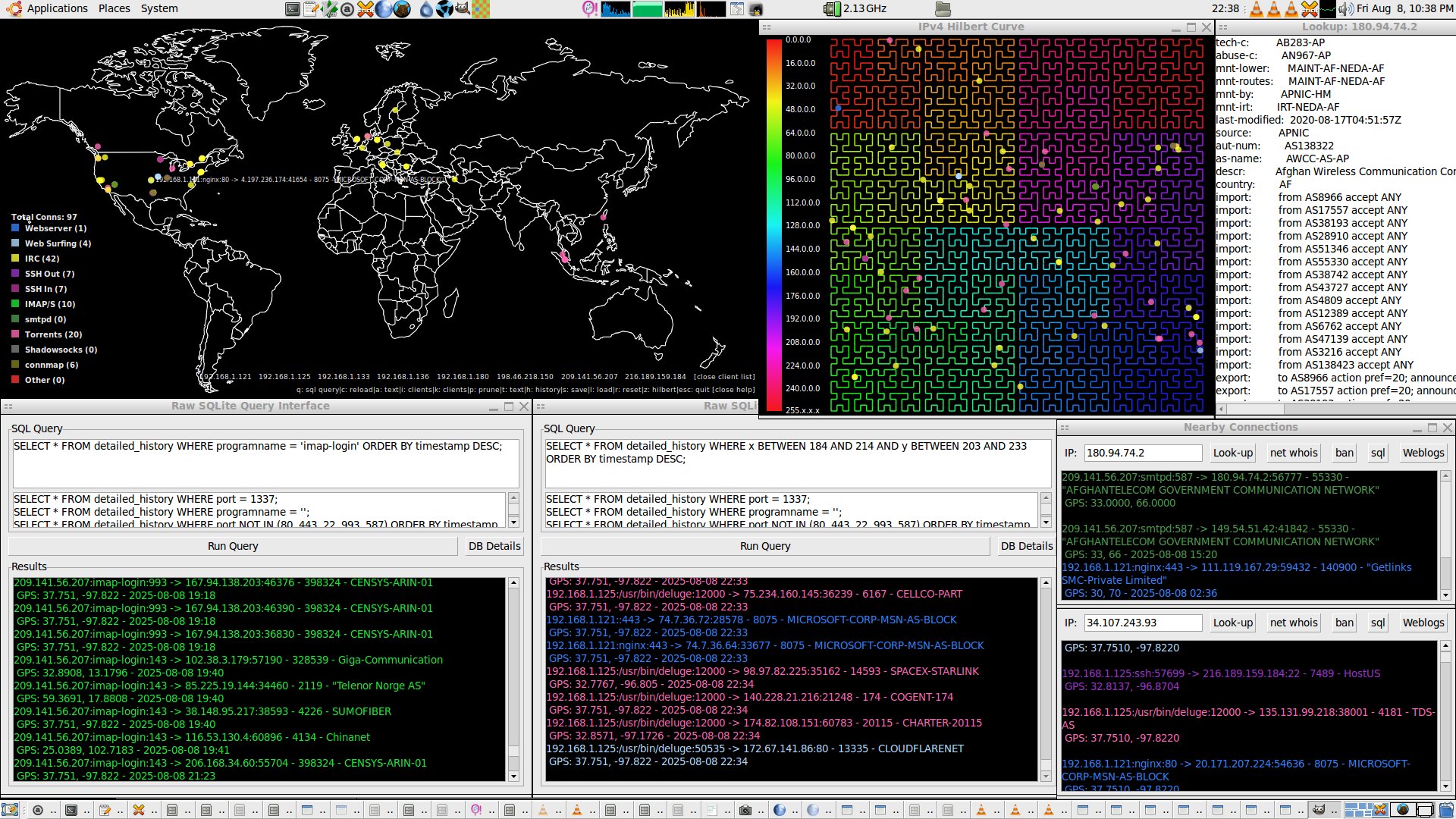
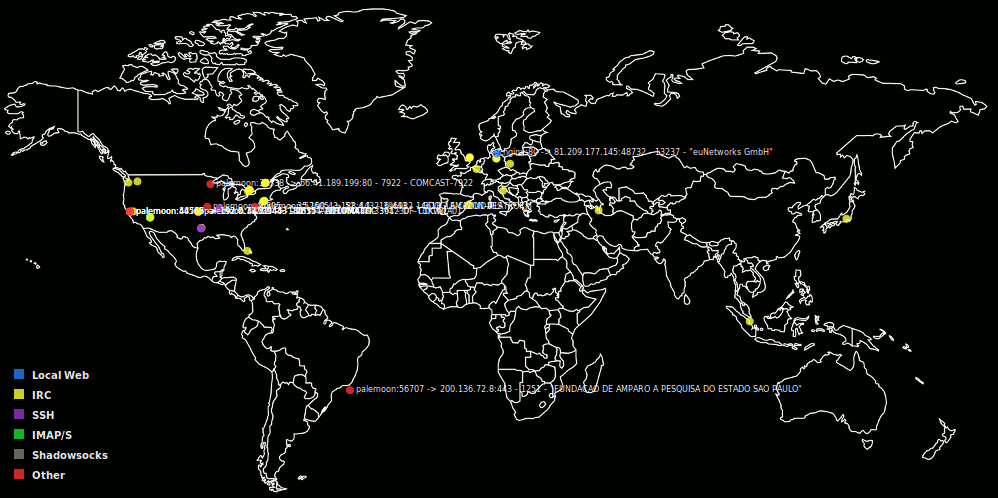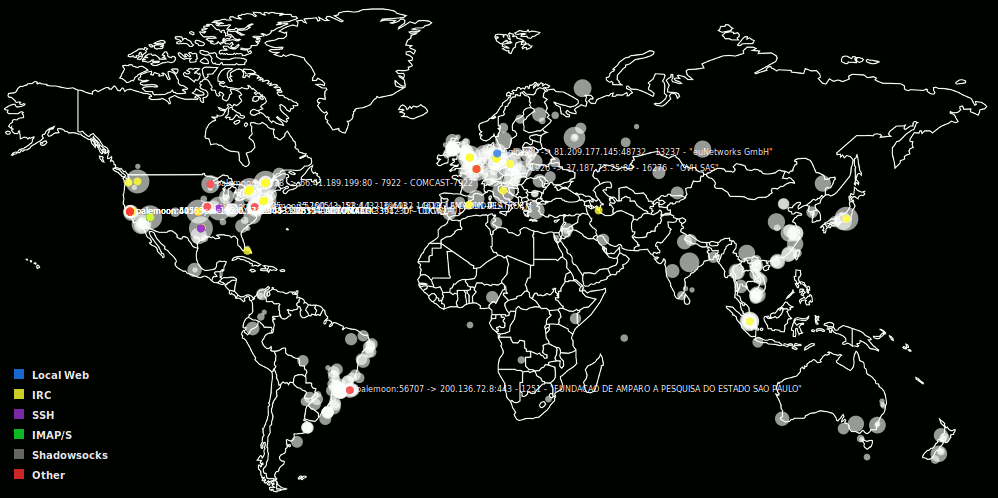
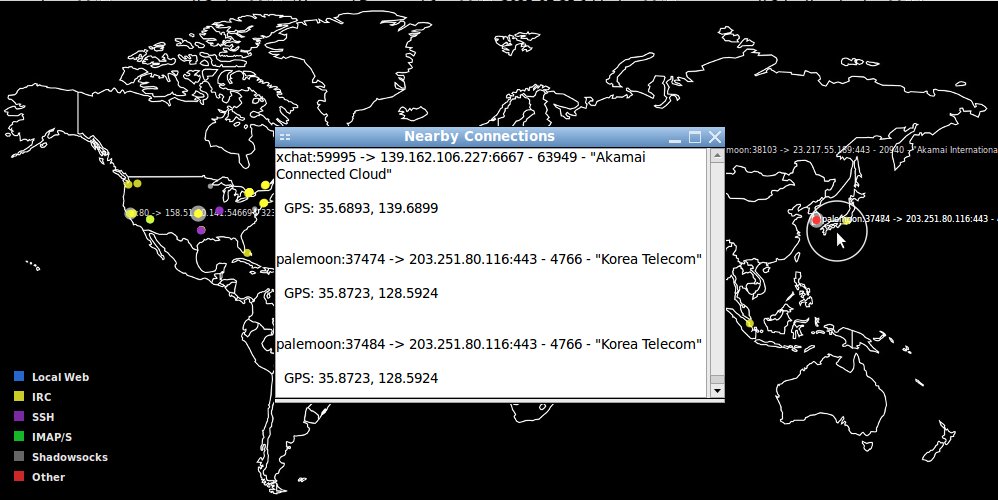
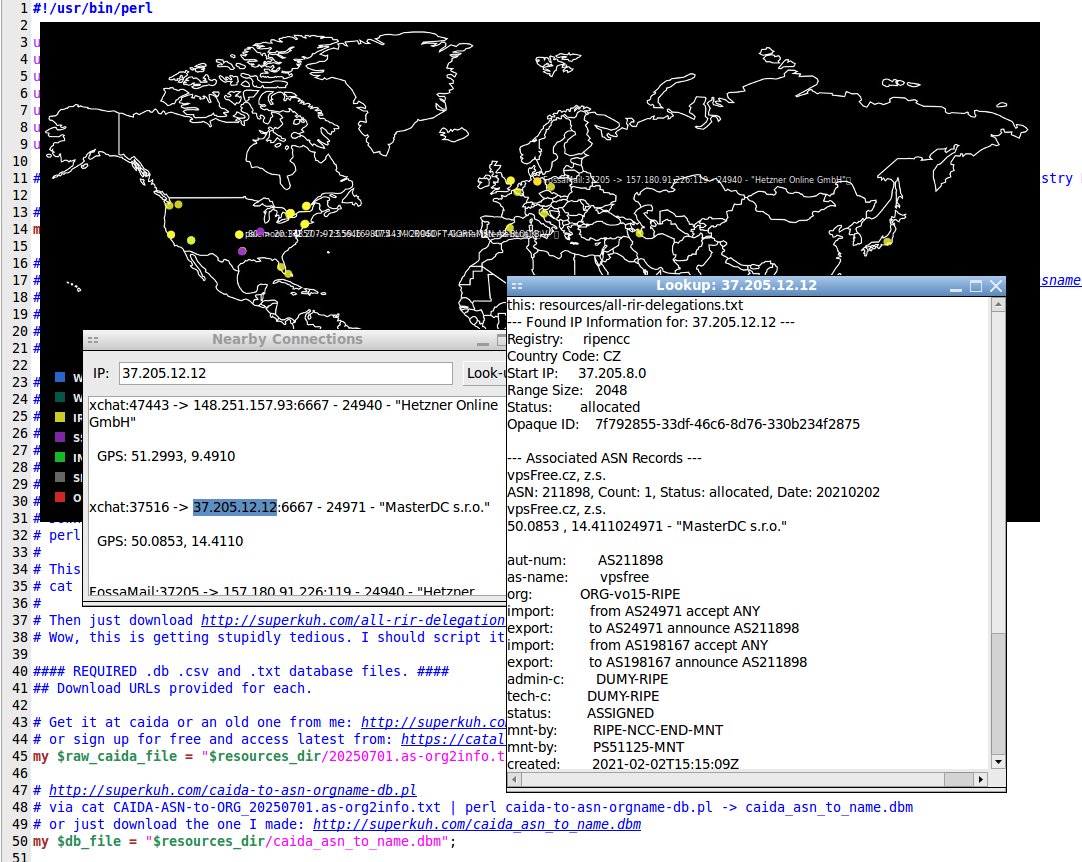
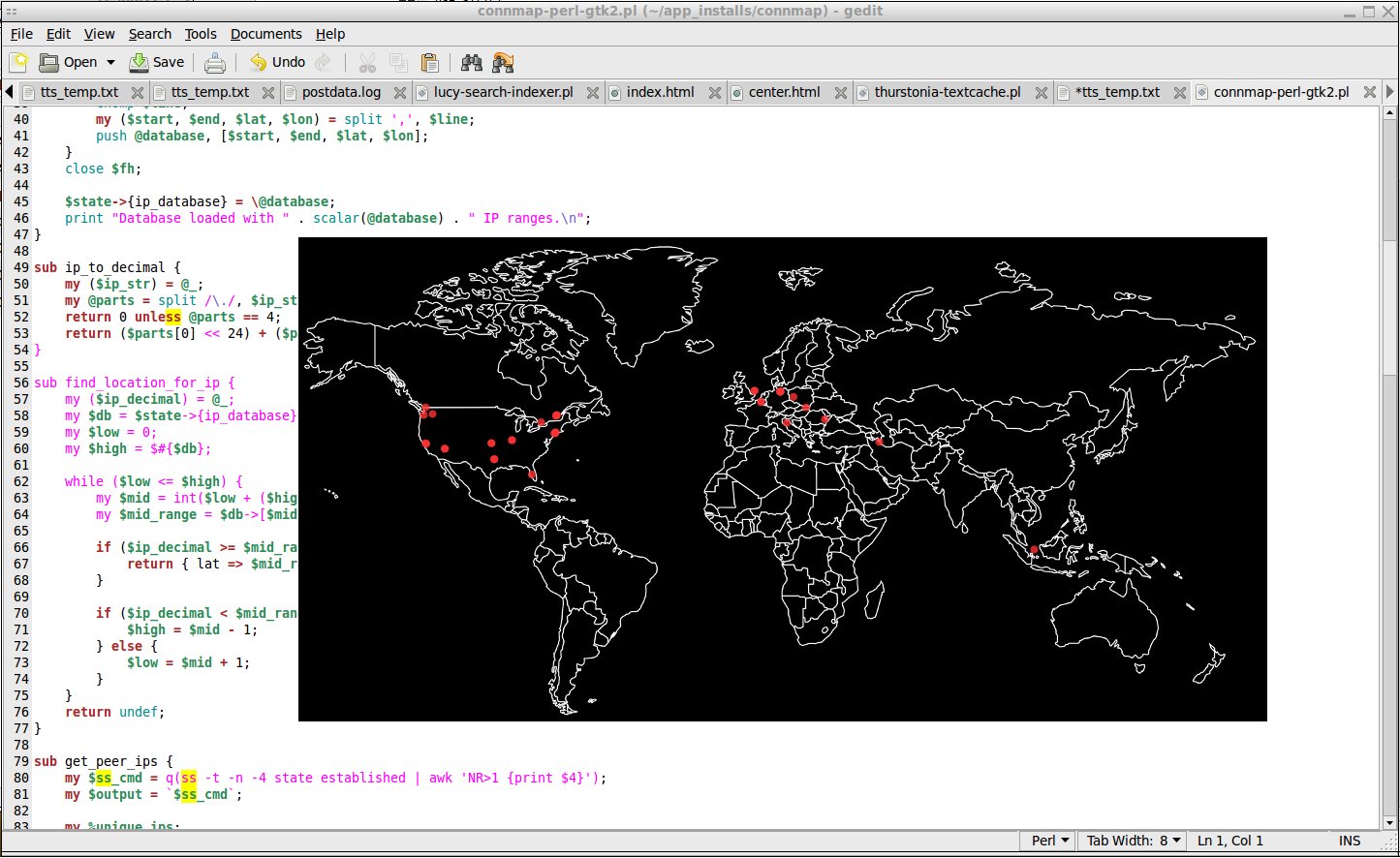
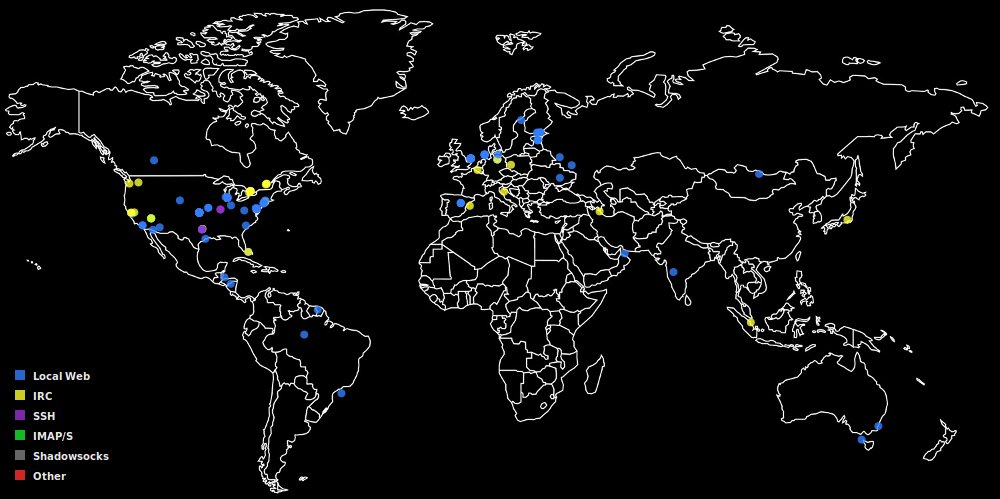
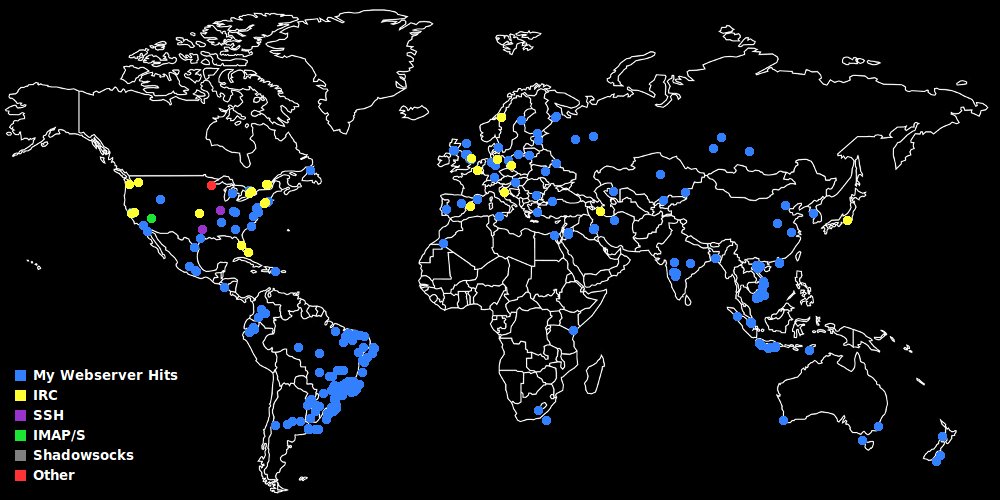






















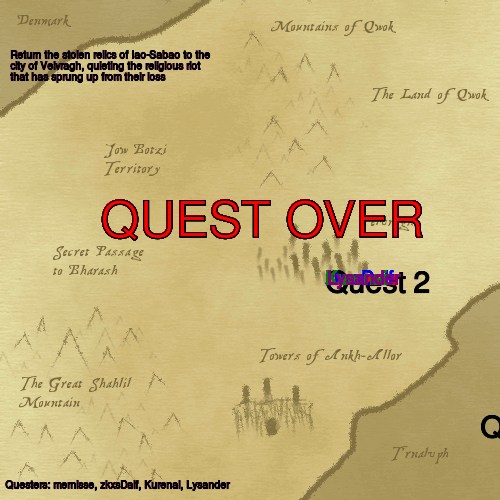
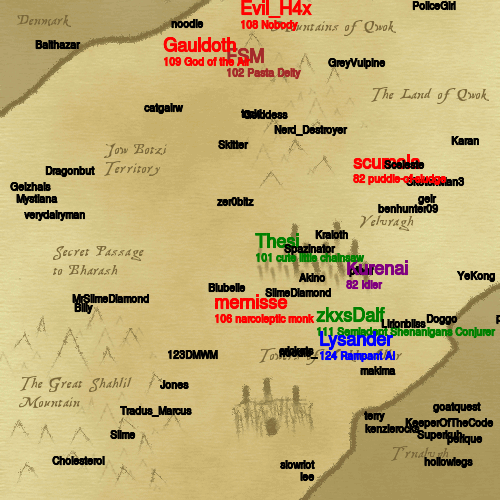


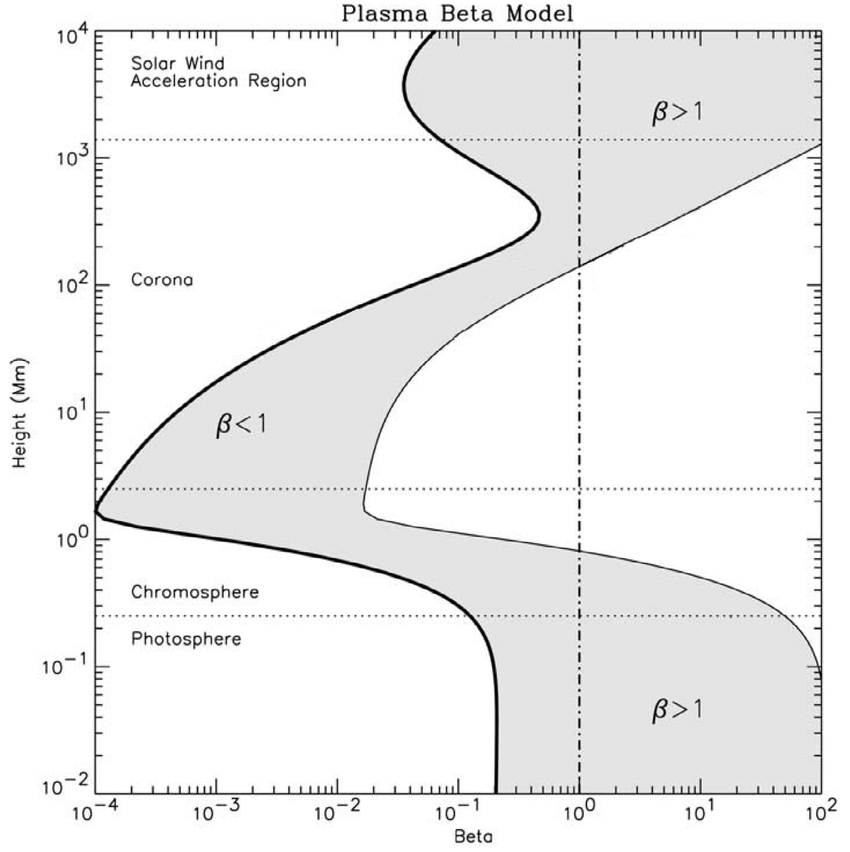
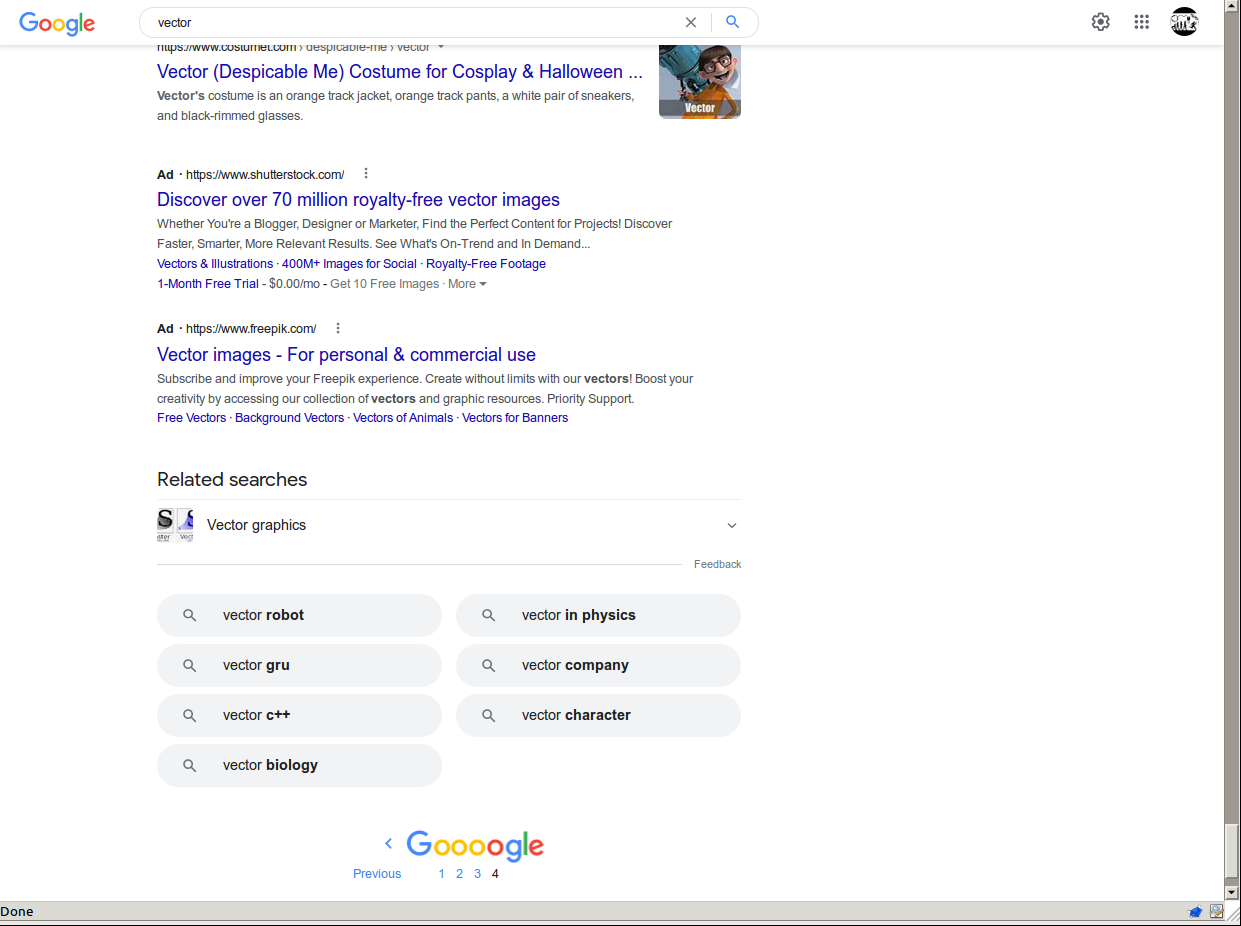










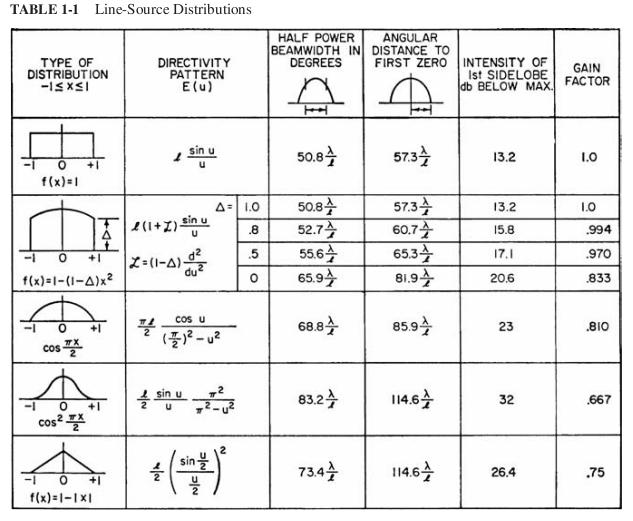






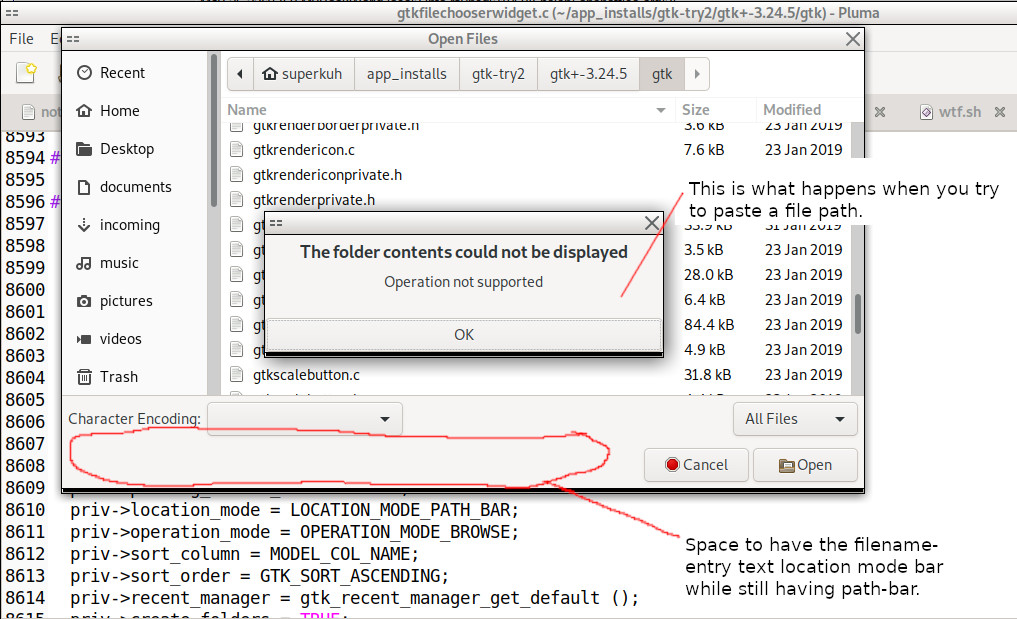








 Step One: Synthesis of A
Methyl acrylate (2.78mol) is added to furan (3.95mol) and cooled to -10*C. AlCl3 in DCM (1.15mol in 1-5M conc.) is added slowly with stirring, keeping the temperature below -10*C. The mixture is then cooled with a cold water bath and stirred for 2 hours. The mixture is added to 1000ml of saturated sodium bicarbonate solution, and the precipitate is filtered out. The aqeous layer is extracted twice with 250ml DCM, and the organic layers are combined and dried over anhydrous sodium sulfate. The solvent is distilled away and the product purified by silica gel column chromatography to give the desired product in 38.6% yield (1.07mol).
Step Two: Synthesis of B
A (1.07mol) is added to NaOH (1.65mol, 3 to 15M concentration) in water with stirring, maintaining a temperature of 5*C. The mixture is allowed to warm up over a period of 30 minutes with stirring, and stirred at room temperature for 2 hours. HCl (310ml of 31% sol.) is added to adjust the pH to below 1, and then the mixture is extracted 4 times with 200ml of DCM. The combined organic layers are dried with Na2SO4, and solvent evaporated and the product recrystallized from ethyl acetate to give the desired product in 87.5% yield (0.936mol).
Step Three: Synthesis of C
B (0.936mol) is dissolved into 850ml water, and NaHCO3 (0.936mol) is added slowly, with stirring to control the foaming. After foaming ceases, bromine (0.936mol) is added dropwise with stirring, and then the mixture is stirred at room temperature for 2 hours. The mixture is extracted with 400ml ethyl acetate, washed with 100ml thiosulfate solution (to remove unreacted bromine) and dried with Na2SO4. The solvent is distilled away and the product purfied by recrystallizing from ethyl acetate, giving the desired product in 89.6% yeild (0.84mol)
Step Four: Synthesis of D
Potassium hydroxide (2.5mol) is dissolved into dimethylacetamide (1000ml) and methanol (150ml), and C (0.84mol) is added slowly as the mixture is heated to a gentle reflux. It is stirred under reflux for 3 hours, then ethyl iodide (1.6mol) is added and the mixture stirred under reflux for another 3 hours. To the mixture is added HCl (300ml 31%) and the solution extracted with ethyl acetate (250ml) eight times. The organic layer is washed with saturated brine and dried with Na2SO4. The solvent is distilled away and the product purified by recrystallization to give the desired product in 95.9% yield (0.804mol).
Step Five: Synthesis of E
A solution of sodium methoxide (0.9mol) in tetrahydrofuran (500ml) is cooled to -30*C, and D (0.804mol) in tetrahydrofuran (500ml) is added dropwise with stirring. After the addition, the mixture is stirred at 30*C for 1hr. To the mixture is added acetic anhydride (1.05mol) and the mixture is stirred at room temperature for 3hr. To the reaction mixture is added saturated ammonium chloride (1000ml), and the mixture is extracted with ethyl acetate (800ml). The organic layer is dried (Na2SO4) and the solvent distilled away. The product is recrystallized (ethyl acetate) to give the desired product in 80.0% yeild (0.644mol).
Step Six: Synthesis of F
E (0.644mol) is dissolved into 3-pentanol (600ml) at reflux, and AlCl3 (0.7mol) is slowly added with stirring. The mixture is stirred at reflux for 1 hour, and then allowed to cool to room temperature. A saturated solution of NaHCO3 is added (1000ml), and the mixture is extracted with 750ml DCM, washed with saturated brine (750ml) and dried with Na2SO4. The solvent is distilled away and the product recrystallized (DCM) to give the desired product in 81.2% yield (0.522mol)
Step Seven: Synthesis of G
F (0.522mol) is dissolved in DCM (750ml) and triethylamine (0.78mol) is added. The mixture is stirred at room temperature for 5 min. and then cooled to 0*C. To the mixture is added tosyl chloride (0.78mol) and the mixture is stirred at room temperature for 1hr. The reaction mixture is washed with saturated sodium bicarbonate solution (1500ml), saturated brine (750ml) and then dried with sodium sulfate. The solvent is distilled off, and the crude product recrystallized from DCM to give G in 97.3% yeild (0.508mol).
Step Eight: Synthesis H
G (0.508mol) is dissolved in ethanol (1000ml) at reflux, and potassium carbonate (0.25mol) is added with stirring. The mixture is stirred at gentle reflux for 1.5 hours, and then cooled to room temperature. Saturated ammonium chloride solution (1000ml) is added. The mixture is extracted with DCM (750ml), washed with saturated brine (1000ml) and dried (Na2SO4). The solvent is distilled away and the crude product recrystallized from DCM to give H in 98.5% yeild (0.5mol).
Step Nine: Synthesis of I
H (0.5mol), sodium azide (0.6mol) and ammonium chloride (0.6mol) are dissolved into water (70ml) and ethanol (250ml), and refluxed for 8 hours. Aqeous NaHCO3 (105ml of 8% solution) is added and the ethanol distilled in vacuum. The aqeous residue is extracted with ethyl acetate (250ml), the extract washed with water (125ml). The wash is back extracted with 125ml of ethyl acetate and the combined organic extracts washed with brine (125ml), dried over Na2SO4, filtered and concentrated in vacuum to give I as a dark brown oil in 102% yield (0.512mol)
Step Ten: Synthesis of J
Step One:
J (0.512mol) and ammonium chloride (1.2mol) are dissolved into ethanol (1500ml), and zinc (0.7mol) is added and the mixture refluxed for 30 minutes. The solvent is distilled off to give Ib, which is used directly in the next step.
Step Two:
Tosysl Chloride (1.13mol) is added portionwise at room temperature to a stirred mixture of Ib (from the step one), K2CO3 (2.5mol) in acetonitrile (1000ml) and stirred for 6hr. Toluene (2500ml) is added, the solid is filtered off and the solvent evaporated to give J in approx 80-90% yeild. It is used directly in the next step without purification.
Step Eleven: Synthesis of K
J (0.494mol), sodium azide (1.2mol) and ammonium chloride (1.2mol) in dimethylacetamide (400ml) is heated to 80-85*C for 5 hours. NaHCO3 (50mmol) in water (250ml) is added, and the mixture extracted with hexanes (6x250ml). The combined hexane extracts are concentrated to 1200ml, and 250ml DCM is added, followed by 1100ml NaHCO3 8% solution and acetic anhydride (0.6mol). The mixture is stirred at room temperature for an hour, and then the aqeous layer is removed. The organic phases are concentrated in vacuum to 430g total weight), dissolved in ethyl acetate (50ml). The mixture is cooled and K crystallizes out and is collected by filtering. The crystals are washed with cold 15% ethyl acetate in hexane (250ml) and dried in a vacuum at room temperature, to give K in 55% yield (0.272mol). [may be slighly higher, ie 60%]
Step Twelve: Synthesis of L (oseltamivir freebase)
K (0.272mol) is dissolved into ethanol (600ml) along with ammonium chloride (0.64mol). Zinc (0.36mol) is added and the mixture refluxed for 30 minutes. The precipitate is filtered out, giving L in 98% yeild (0.266mol). [90-95% more likely]
Step Thirteen: Synthesis of Oseltamivir Phosphate
L (0.266mol) is dissolved in acetone (1000ml) and treated with phosphoric acid (85%, 0.266mol) in absolute ethanol (300ml). The mixture is cooled, and after 12 hours the precipitate is filtered out to give oseltamivir phosphate in 75% yield (0.2mol, 82g). A second crop of presumably lower purity crystals can be obtained by concentrated the solution and collecting a second crop of product.
Step One: Synthesis of A
Methyl acrylate (2.78mol) is added to furan (3.95mol) and cooled to -10*C. AlCl3 in DCM (1.15mol in 1-5M conc.) is added slowly with stirring, keeping the temperature below -10*C. The mixture is then cooled with a cold water bath and stirred for 2 hours. The mixture is added to 1000ml of saturated sodium bicarbonate solution, and the precipitate is filtered out. The aqeous layer is extracted twice with 250ml DCM, and the organic layers are combined and dried over anhydrous sodium sulfate. The solvent is distilled away and the product purified by silica gel column chromatography to give the desired product in 38.6% yield (1.07mol).
Step Two: Synthesis of B
A (1.07mol) is added to NaOH (1.65mol, 3 to 15M concentration) in water with stirring, maintaining a temperature of 5*C. The mixture is allowed to warm up over a period of 30 minutes with stirring, and stirred at room temperature for 2 hours. HCl (310ml of 31% sol.) is added to adjust the pH to below 1, and then the mixture is extracted 4 times with 200ml of DCM. The combined organic layers are dried with Na2SO4, and solvent evaporated and the product recrystallized from ethyl acetate to give the desired product in 87.5% yield (0.936mol).
Step Three: Synthesis of C
B (0.936mol) is dissolved into 850ml water, and NaHCO3 (0.936mol) is added slowly, with stirring to control the foaming. After foaming ceases, bromine (0.936mol) is added dropwise with stirring, and then the mixture is stirred at room temperature for 2 hours. The mixture is extracted with 400ml ethyl acetate, washed with 100ml thiosulfate solution (to remove unreacted bromine) and dried with Na2SO4. The solvent is distilled away and the product purfied by recrystallizing from ethyl acetate, giving the desired product in 89.6% yeild (0.84mol)
Step Four: Synthesis of D
Potassium hydroxide (2.5mol) is dissolved into dimethylacetamide (1000ml) and methanol (150ml), and C (0.84mol) is added slowly as the mixture is heated to a gentle reflux. It is stirred under reflux for 3 hours, then ethyl iodide (1.6mol) is added and the mixture stirred under reflux for another 3 hours. To the mixture is added HCl (300ml 31%) and the solution extracted with ethyl acetate (250ml) eight times. The organic layer is washed with saturated brine and dried with Na2SO4. The solvent is distilled away and the product purified by recrystallization to give the desired product in 95.9% yield (0.804mol).
Step Five: Synthesis of E
A solution of sodium methoxide (0.9mol) in tetrahydrofuran (500ml) is cooled to -30*C, and D (0.804mol) in tetrahydrofuran (500ml) is added dropwise with stirring. After the addition, the mixture is stirred at 30*C for 1hr. To the mixture is added acetic anhydride (1.05mol) and the mixture is stirred at room temperature for 3hr. To the reaction mixture is added saturated ammonium chloride (1000ml), and the mixture is extracted with ethyl acetate (800ml). The organic layer is dried (Na2SO4) and the solvent distilled away. The product is recrystallized (ethyl acetate) to give the desired product in 80.0% yeild (0.644mol).
Step Six: Synthesis of F
E (0.644mol) is dissolved into 3-pentanol (600ml) at reflux, and AlCl3 (0.7mol) is slowly added with stirring. The mixture is stirred at reflux for 1 hour, and then allowed to cool to room temperature. A saturated solution of NaHCO3 is added (1000ml), and the mixture is extracted with 750ml DCM, washed with saturated brine (750ml) and dried with Na2SO4. The solvent is distilled away and the product recrystallized (DCM) to give the desired product in 81.2% yield (0.522mol)
Step Seven: Synthesis of G
F (0.522mol) is dissolved in DCM (750ml) and triethylamine (0.78mol) is added. The mixture is stirred at room temperature for 5 min. and then cooled to 0*C. To the mixture is added tosyl chloride (0.78mol) and the mixture is stirred at room temperature for 1hr. The reaction mixture is washed with saturated sodium bicarbonate solution (1500ml), saturated brine (750ml) and then dried with sodium sulfate. The solvent is distilled off, and the crude product recrystallized from DCM to give G in 97.3% yeild (0.508mol).
Step Eight: Synthesis H
G (0.508mol) is dissolved in ethanol (1000ml) at reflux, and potassium carbonate (0.25mol) is added with stirring. The mixture is stirred at gentle reflux for 1.5 hours, and then cooled to room temperature. Saturated ammonium chloride solution (1000ml) is added. The mixture is extracted with DCM (750ml), washed with saturated brine (1000ml) and dried (Na2SO4). The solvent is distilled away and the crude product recrystallized from DCM to give H in 98.5% yeild (0.5mol).
Step Nine: Synthesis of I
H (0.5mol), sodium azide (0.6mol) and ammonium chloride (0.6mol) are dissolved into water (70ml) and ethanol (250ml), and refluxed for 8 hours. Aqeous NaHCO3 (105ml of 8% solution) is added and the ethanol distilled in vacuum. The aqeous residue is extracted with ethyl acetate (250ml), the extract washed with water (125ml). The wash is back extracted with 125ml of ethyl acetate and the combined organic extracts washed with brine (125ml), dried over Na2SO4, filtered and concentrated in vacuum to give I as a dark brown oil in 102% yield (0.512mol)
Step Ten: Synthesis of J
Step One:
J (0.512mol) and ammonium chloride (1.2mol) are dissolved into ethanol (1500ml), and zinc (0.7mol) is added and the mixture refluxed for 30 minutes. The solvent is distilled off to give Ib, which is used directly in the next step.
Step Two:
Tosysl Chloride (1.13mol) is added portionwise at room temperature to a stirred mixture of Ib (from the step one), K2CO3 (2.5mol) in acetonitrile (1000ml) and stirred for 6hr. Toluene (2500ml) is added, the solid is filtered off and the solvent evaporated to give J in approx 80-90% yeild. It is used directly in the next step without purification.
Step Eleven: Synthesis of K
J (0.494mol), sodium azide (1.2mol) and ammonium chloride (1.2mol) in dimethylacetamide (400ml) is heated to 80-85*C for 5 hours. NaHCO3 (50mmol) in water (250ml) is added, and the mixture extracted with hexanes (6x250ml). The combined hexane extracts are concentrated to 1200ml, and 250ml DCM is added, followed by 1100ml NaHCO3 8% solution and acetic anhydride (0.6mol). The mixture is stirred at room temperature for an hour, and then the aqeous layer is removed. The organic phases are concentrated in vacuum to 430g total weight), dissolved in ethyl acetate (50ml). The mixture is cooled and K crystallizes out and is collected by filtering. The crystals are washed with cold 15% ethyl acetate in hexane (250ml) and dried in a vacuum at room temperature, to give K in 55% yield (0.272mol). [may be slighly higher, ie 60%]
Step Twelve: Synthesis of L (oseltamivir freebase)
K (0.272mol) is dissolved into ethanol (600ml) along with ammonium chloride (0.64mol). Zinc (0.36mol) is added and the mixture refluxed for 30 minutes. The precipitate is filtered out, giving L in 98% yeild (0.266mol). [90-95% more likely]
Step Thirteen: Synthesis of Oseltamivir Phosphate
L (0.266mol) is dissolved in acetone (1000ml) and treated with phosphoric acid (85%, 0.266mol) in absolute ethanol (300ml). The mixture is cooled, and after 12 hours the precipitate is filtered out to give oseltamivir phosphate in 75% yield (0.2mol, 82g). A second crop of presumably lower purity crystals can be obtained by concentrated the solution and collecting a second crop of product.



{kind=link}